Program 10a: Multiple Regression
Using a linked list, write a program to calculate the 3-parameter multiple regression parameters and the prediction interval.
Given Requirements
Requirements: Write a program to calculate the three-variable multiple regression estimation parameters, make an estimate from user-supplied inputs, and determine the 70 percent and 90 percent prediction intervals. The formulas and methods for doing this calculation are described in sections A9, A10, and A11 [of the text]... Further enhance the linked list from program 4a. Testing: Thoroughly test the program. As one test, use the data in Table D16. For the estimated values, use 185 LOC of new code, 150 LOC of reused code, and 45 LOC of modified code. The projected hours should be 20.76 hours, the 90 percent UPI is 33.67 hours, and the 90 percent LPI is 7.84 hours. The 70 percent prediction interval is from 14.63 to 26.89 hours. The values of the beta parameters are Beta0 = 0.56645, Beta1 = 0.06533, Beta2 = 0.008719, and Beta3 = 0.15105. These are equivalent to productivities of 15.3 new and changed LOC per hour, reuse of 114.7 LOC per hour, and modification of 6.6 LOC per hour. As a further test case you should also verify that your program produces the same results given in the examples in sections A9 and A10 (pages 554 and 558). Submit a test report giving your results in the format in Table D17. Table 11-1. D16: Multiple Regression Exercise Data
Table 11-2. D17: Test Results Format -- Program 10A
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| --[Humphrey95] | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Planning
Requirements
The requirements are pretty straightforward. I'll be enhancing program 9a for this one, and in program 9a we took the point of view that after the historical data we should have a list of commands with arguments. The new command to be used will be multiple-regression-prediction x-value, y-value, z-value, .... That way, we can extend the wee little command set of this program and make the most of code reuse.
In keeping with program 9a, program 10a should be able to handle input arrays of any reasonable size (ie should fit in memory)-- any field width, etc. That may seem to make the design more complicated, but if I'm right it will actually be easier to code a general solution than a specific one in this case.
Output will be in much the same format as program 9a. Output from the multiple-regression-prediction command will be as follows:
Multiple Regression Prediction: Solution: ( 0.56645, 0.06544, ... 0.15105 ) variance : ... standard deviation : ... Prediction from values ( w, x, y...): Projected Result: 20.76 UPI( 70% ): 26.89 LPI( 70% ): 14.63 UPI( 90% ): 33.67 LPI( 90% ): 7.84 |
Errors in the program's execution (invalid input, too few parameters for calculations, etc) should be recognized and displayed using stderr.
Size Estimate
I'm a little confused, I confess, about the difference between the "conceptual design" which I've generated in the past to form size estimates, and the "high-level design" described in the PSP3 process, which comes after the size and time estimates. With that in mind, I'm still going to make a fairly high-level design for the size estimate.
With that brief design, PROBE gets me an initial estimate of only 239 new/changed LOC. Considering that the book repeatedly notes that program 10 is large enough that multiple sessions are usually necessary, this seems very optimistic (it's the same amount that PROBE predicted for program 9a). We'll see what comes of it. I have divided the size estimate into the first cycle (building the gaussian_solver class, about 104 LOC) and a second cycle (fleshing out the number_array_list_parser_2 structure and modifying the parser, about 135 LOC). These estimates do not include test scaffolding for the first cycle; I'm not sure how to handle that, but it will only be a few LOC, which won't be included in the final.
Resource/Time Estimate
With the PROBE-generated estimate of 239 new/changed LOC, I get an estimate of 285 minutes for program 10a, with about 89 minutes going to the first cycle and 119 in the second cycle.
High-level Design and Design Review
I actually find myself wishing that Humphrey had decided on a completely different project for program 10a; I want to start using high-level design and design reviews, but the bulk of the high-level design has already been done in the form of previous projects-- and as much as I'd like to further my knowledge, I can't bring myself to reinvent the wheel. The basic structure of parsing textual input using a derivative of the simple_input_parser has worked well, and I'm simply expanding on that, so much of the high-level design has been encapsulated in earlier work. User operation scenarios are therefore sparse. Since few of my objects have any explicit state (except for values), it's tough to call parts of this a "state machine" except in the sense that number_array_lists have contents, the gaussian_solver has an "is_solvable" state, etc. But when requirements for certain "states" (is_solvable, for example) are encoded into contracts for other routines, it seems odd to specify a "state transition" rather than simply specifying the "is_solvable" evaluation. And most of the function-level specification will be done at the cycle level rather than the high-level design level.
In addition, the high-level design was supposed to be used to break down the development into cycles of around 100 LOC-- but I had already done that in the planning phase! So I'm afraid the high-level design and design reviews, while interesting, were not particularly useful for program 10a.
Development
Cycle 1: Gaussian Solver
Design
Basic design for the gaussian solver chunk fleshed out the gaussian_solver class and added a test stub to the main program; the brief diagram is below. Because much code for adding and summing arrays of numbers was coming up in gaussian_solver, I eventually broke that out into its own class, numeric_array.
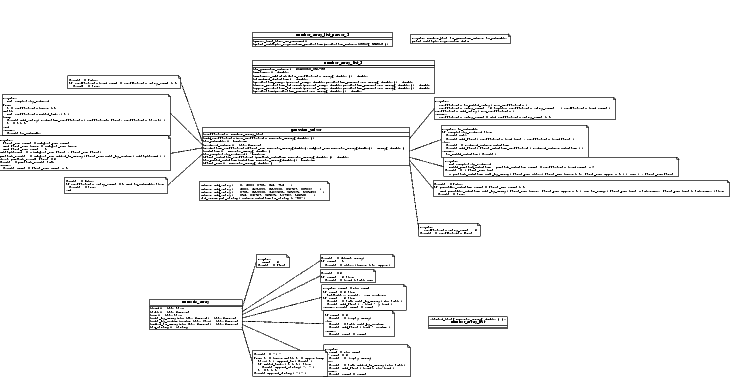
Design Review
The PSP3 process adds something to the design review, a bit about using "...defined methods such as execution tables, trace tables, or mathematical verification" [Humphrey95]. For program 10a-- and I'm not sure why-- I did not follow this advice on either cycle; in fact, it's safe to say that the design reviews for program 10a were done more sloppily than for any program to date (where design reviews were done).
I'm not sure why this is-- perhaps I was tired and fell into old habits, perhaps I was overconfident about my initial design-- but I paid the price. Program 10a took significantly longer than expected, mostly for silly errors that I could have caught with a design review.
Code
Reused Code
Much code was reused for this program, including the classes adder, chi_squared_base, chi_squared_integral, error_log, gamma_function, is_double_equal, normal_distribution_integral, normal_distribution_inverse, normal_function_base, normalizer, simple_input_parser, simpson_integrator, single_variable_function, square, t_distribution, t_distribution_base, t_integral, and whitespace_stripper classes. Much of the code from the number_array_list and number_array_list_parser classes from previous programs were used. The main.cpp and main.e files were used intact with the minor change of the parser type; they are not reproduced here.
gaussian_solver
#ifndef GAUSSIAN_SOLVER_H
#define GAUSSIAN_SOLVER_H
#ifndef NUMERIC_ARRAY_H
#include "numeric_array.h"
#endif
class number_array_list_3;
class gaussian_solver_imp;
class gaussian_solver
{
protected:
gaussian_solver_imp* m_pimp;
const number_array_list_3& coefficients( void ) const;
public:
void add_coefficients( const numeric_array& new_coefficients );
numeric_array solution( void ) const;
public:
gaussian_solver( void );
gaussian_solver( const gaussian_solver& rhs );
~gaussian_solver( void );
public:
bool is_solvable( void ) const;
gaussian_solver reduced_solver( void ) const;
numeric_array reduction_coefficients( const numeric_array& first, const numeric_array& subject ) const;
bool is_completely_reduced( void ) const;
double first_solution_coefficient( const numeric_array& partial_solution ) const;
bool is_valid_solution( const numeric_array& test_solution ) const;
numeric_array first_row( void ) const;
};
#endif |
#include "gaussian_solver.h"
#ifndef CONTRACT_H
#include "contract.h"
#endif
#ifndef IS_DOUBLE_EQUAL_H
#include "is_double_equal.h"
#endif
#ifndef NUMBER_ARRAY_LIST_3_H
#include "number_array_list_3.h"
#endif
class gaussian_solver_imp
{
public:
number_array_list_3 coefficients;
};
gaussian_solver::gaussian_solver( void )
{
m_pimp = new gaussian_solver_imp;
}
gaussian_solver::gaussian_solver( const gaussian_solver& rhs )
{
m_pimp = new gaussian_solver_imp;
m_pimp->coefficients = rhs.coefficients();
}
gaussian_solver::~gaussian_solver( void )
{
REQUIRE( m_pimp != NULL );
delete m_pimp;
}
const number_array_list_3&
gaussian_solver::coefficients( void ) const
{
REQUIRE( m_pimp != NULL );
return m_pimp->coefficients;
}
void
gaussian_solver::add_coefficients( const numeric_array& new_coefficients )
{
REQUIRE( coefficients().is_valid_entry( new_coefficients ) );
if ( coefficients().entry_count() > 0 )
{
REQUIRE( coefficients().entry_count() < coefficients().head().size() );
}
m_pimp->coefficients.add_entry( new_coefficients );
}
numeric_array
gaussian_solver::solution( void ) const
{
REQUIRE( is_solvable() );
numeric_array Result;
if ( is_completely_reduced() )
{
Result.push_back( coefficients().head()[1] / coefficients().head()[0] );
}
else
{
Result = reduced_solver().solution();
Result.insert( Result.begin(), first_solution_coefficient( Result ) );
}
ENSURE( is_valid_solution( Result ) );
return Result;
}
bool
gaussian_solver::is_solvable( void ) const
{
bool Result = false;
if ( coefficients().field_count() == coefficients().entry_count() + 1 )
{
Result = true;
}
return Result;
}
gaussian_solver
gaussian_solver::reduced_solver( void ) const
{
REQUIRE( !is_completely_reduced() );
gaussian_solver Result;
number_array_list_3::const_iterator iter = coefficients().begin();
++iter;
while( iter != coefficients().end() )
{
Result.add_coefficients( reduction_coefficients( coefficients().head(), *iter ) );
++iter;
}
ENSURE( Result.is_solvable() );
return Result;
}
numeric_array
gaussian_solver::reduction_coefficients( const numeric_array& first, const numeric_array& subject ) const
{
REQUIRE( first.size() == subject.size() );
REQUIRE( first.size() > 1 );
const double multiplicand = ( - subject.head() / first.head() );
const numeric_array partial_result = subject.added_to_array( first.mult_by_scalar( multiplicand ) );
CHECK( is_double_equal( partial_result.head(), 0 ) );
numeric_array Result = partial_result.tail();
ENSURE( Result.size() == first.size() - 1 );
return Result;
}
bool
gaussian_solver::is_completely_reduced( void ) const
{
bool Result = false;
if ( ( coefficients().entry_count() == 1 ) && is_solvable() )
{
Result = true;
}
return Result;
}
double
gaussian_solver::first_solution_coefficient( const numeric_array& partial_solution ) const
{
REQUIRE( !is_completely_reduced() );
REQUIRE( partial_solution.size() == coefficients().head().size() - 2 );
numeric_array middle_section;
numeric_array::const_iterator middle_begin = first_row().begin();
++middle_begin;
numeric_array::const_iterator middle_end = first_row().end();
--middle_end;
middle_section.insert( middle_section.begin(), middle_begin, middle_end );
const double x = first_row()[0];
const double y = partial_solution.mult_by_array( middle_section ).sum();
const double z = first_row()[ first_row().size() - 1 ];
double Result = ( z - y ) / x;
return Result;
}
bool
gaussian_solver::is_valid_solution( const numeric_array& test_solution ) const
{
bool Result = false;
numeric_array first_row_arguments = first_row();
first_row_arguments.pop_back();
if ( ( test_solution.size() == first_row().size() - 1 )
&& ( test_solution.mult_by_array( first_row_arguments ).sum() == first_row()[ first_row().size() - 1 ] ) )
{
Result = true;
}
return Result;
}
numeric_array
gaussian_solver::first_row( void ) const
{
return coefficients().head();
} |
class GAUSSIAN_SOLVER
creation {ANY}
make
feature {ANY}
coefficients: NUMBER_ARRAY_LIST_3;
feature {ANY}
make is
--creation
do
!!coefficients.make;
end -- make
add_coefficients(new_coefficients: NUMERIC_ARRAY) is
--adds a set of coefficients to the list
require
coefficients.is_valid_entry(new_coefficients);
coefficients.entry_count > 0 implies coefficients.entry_count + 1 < coefficients.head.count;
do
coefficients.add_entry(new_coefficients);
ensure
coefficients.entry_count = old coefficients.entry_count + 1;
end -- add_coefficients
is_solvable: BOOLEAN is
--is the current set of coefficients solvable?
do
Result := false;
if coefficients.head.count = coefficients.entry_count + 1 then
Result := true;
end;
end -- is_solvable
reduced_solver: like Current is
--solver, "reduced" by one equation and one parameter
require
not completely_reduced;
local
i: INTEGER;
do
!!Result.make;
from
i := coefficients.lower + 1;
until
not coefficients.valid_index(i)
loop
Result.add_coefficients(reduction_coefficients(coefficients.first,coefficients.item(i)));
i := i + 1;
end;
ensure
Result.is_solvable;
end -- reduced_solver
reduction_coefficients(first, subject: NUMERIC_ARRAY): NUMERIC_ARRAY is
--the coefficients used to reduce the solver; mostly used internally
require
first.count = subject.count;
first.lower = subject.lower;
first.count > 1;
local
multiplicand: DOUBLE;
partial_result: NUMERIC_ARRAY;
do
multiplicand := - (subject.head / first.head);
partial_result := subject.added_to_array(first.mult_by_scalar(multiplicand));
check
partial_result.head.in_range(- 0.0000001,0.0000001);
end;
Result := partial_result.tail;
ensure
Result.count = first_row.count - 1;
end -- reduction_coefficients
solution: NUMERIC_ARRAY is
--beta parameters for the multiple regression solution
require
is_solvable;
do
if completely_reduced then
!!Result.make_empty;
Result.add_first(coefficients.head.last / coefficients.head.first);
else
Result := reduced_solver.solution;
Result.add_first(first_solution_coefficient(reduced_solver.solution));
end;
ensure
is_valid_solution(Result);
end -- solution
completely_reduced: BOOLEAN is
--is reduced to one equation with two unknowns?
do
Result := false;
if coefficients.entry_count = 1 and is_solvable then
Result := true;
end;
end -- completely_reduced
first_solution_coefficient(partial_solution: NUMERIC_ARRAY): DOUBLE is
--first coefficient to the solution with the given
--parameters for the other coefficients
require
not completely_reduced;
valid_partial_solution: partial_solution.count = coefficients.head.count - 2;
do
Result := (first_row.last - partial_solution.mult_by_array(first_row.slice(first_row.lower + 1,first_row.upper - 1)).sum) / first_row.first;
end -- first_solution_coefficient
is_valid_solution(possible_solution: NUMERIC_ARRAY): BOOLEAN is
--is test_solution a valid solution for the given matrix?
do
Result := false;
if possible_solution.count = first_row.count - 1 and possible_solution.mult_by_array(first_row.slice(first_row.lower,first_row.upper - 1)).sum.in_range(first_row.last - 0.0000001,first_row.last + 0.0000001) then
Result := true;
end;
end -- is_valid_solution
first_row: NUMERIC_ARRAY is
--first row of the coefficients
require
coefficients.entry_count > 0;
do
Result := coefficients.first;
end -- first_row
end -- class GAUSSIAN_SOLVER |
numeric_array
/*
*/
#ifndef NUMERIC_ARRAY_H
#define NUMERIC_ARRAY_H
#include <vector>
#include <string>
class numeric_array : public std::vector< double >
{
public:
double head( void ) const;
numeric_array tail( void ) const;
double sum( void ) const;
numeric_array mult_by_array( const numeric_array& rhs ) const;
numeric_array mult_by_scalar( double scalar ) const;
numeric_array added_to_array( const numeric_array& rhs ) const;
std::string to_string( void ) const;
};
#endif
/*
*/ |
/*
*/
#include "numeric_array.h"
#ifndef CONTRACT_H
#include "contract.h"
#endif
#include <stdio.h>
#include <string>
double
numeric_array::head( void ) const
{
REQUIRE( size() > 0 );
return *begin();
}
numeric_array
numeric_array::tail( void ) const
{
numeric_array Result;
if ( size() > 1 )
{
numeric_array::const_iterator iter = begin();
++iter;
Result.insert( Result.begin(), iter, end() );
}
return Result;
}
double
numeric_array::sum( void ) const
{
double Result = 0;
if ( size() > 0 )
{
Result = head() + tail().sum();
}
return Result;
}
numeric_array
numeric_array::mult_by_array( const numeric_array& rhs ) const
{
REQUIRE( size() == rhs.size() );
numeric_array Result;
if ( size() > 0 )
{
Result = tail().mult_by_array( rhs.tail() );
Result.insert( Result.begin(), head() * rhs.head() );
}
ENSURE( Result.size() == size() );
return Result;
}
numeric_array
numeric_array::mult_by_scalar( double scalar ) const
{
numeric_array Result;
if ( size() > 0 )
{
Result = tail().mult_by_scalar( scalar );
Result.insert( Result.begin(), head() * scalar );
}
ENSURE( Result.size() == size() );
return Result;
}
numeric_array
numeric_array::added_to_array( const numeric_array& rhs ) const
{
numeric_array Result;
if ( size() > 0 )
{
Result = tail().added_to_array( rhs.tail() );
Result.insert( Result.begin(), head() + rhs.head() );
}
ENSURE( Result.size() == size() );
return Result;
}
static std::string double_as_string( double x )
{
char buffer[ 1000 ];
sprintf( buffer, "%f", x );
return std::string( buffer );
}
std::string
numeric_array::to_string( void ) const
{
std::string Result = "( ";
for( numeric_array::const_iterator iter = begin(); iter != end(); ++iter )
{
Result.append( double_as_string( *iter ) );
if ( iter + 1 != end() )
{
Result.append( ", " );
}
}
Result.append( " )" );
return Result;
}
/*
*/ |
class NUMERIC_ARRAY
--simple array of numbers; handles some mappings and functionality
--like NUMBER_ARRAY_LIST and its descendants
inherit
ARRAY[DOUBLE];
creation {ANY}
make, make_empty, with_capacity, from_collection
feature {ANY}
make_empty is
--creates with empty array and indices (1,0) for lower, upper
do
make(1,0);
end -- make_empty
head: like item is
--first item in the array
require
count > 0;
do
Result := first;
end -- head
tail: like Current is
--items in the array after the first
do
if count > 1 then
Result := slice(lower + 1,upper);
else
!!Result.make_empty;
end;
ensure
count > 0 implies Result.count = count - 1;
end -- tail
sum: like item is
--sum of the items in the array
do
Result := 0;
if count > 0 then
Result := head + tail.sum;
end;
end -- sum
mult_by_array(rhs: like Current): like Current is
--each item in the array multiplied by a corresponding element
--in the second array
require
count = rhs.count;
do
if count = 0 then
!!Result.make_empty;
else
Result := tail.mult_by_array(rhs.tail);
Result.add_first(head * rhs.head);
end;
end -- mult_by_array
mult_by_scalar(scalar: like item): like Current is
--each item in the array multiplied by a scalar
do
if count = 0 then
!!Result.make_empty;
else
Result := tail.mult_by_scalar(scalar);
Result.add_first(head * scalar);
end;
end -- mult_by_scalar
added_to_array(rhs: like Current): like Current is
--each item in the array added to the corresponding element in rhs
require
count = rhs.count;
do
if count = 0 then
!!Result.make_empty;
else
Result := tail.added_to_array(rhs.tail);
Result.add_first(head + rhs.head);
end;
end -- added_to_array
to_string: STRING is
--string representation in the form "( x0, x1, ... xn )"
local
i: INTEGER;
do
!!Result.make_from_string("( ");
from
i := lower;
until
not valid_index(i)
loop
item(i).append_in(Result);
if valid_index(i + 1) then
Result.append_string(", ");
end;
i := i + 1;
end;
Result.append_string(" )");
end -- to_string
end -- class NUMERIC_ARRAY |
Code Review
Sigh... much as the design reviews suffered, so did the code reviews, to the point that I had double the number of defects reaching compile as I had expected. Disappointing, but I realize it was my fault for lacking some necessary discipline.
Compile
No surprises except for double the number of defects injected in code as I'd expected. Ouch.
Test
Actually, test went well, finding one fewer defect than expected and taking as much time as predicted. Around here, I felt I was doing well with program 10a.
Cycle 2: Multiple Regression
Design
Only a little more thought went into design of cycle 2, because it was mostly enhancements for the number_array_list and number_array_list_parser classes.
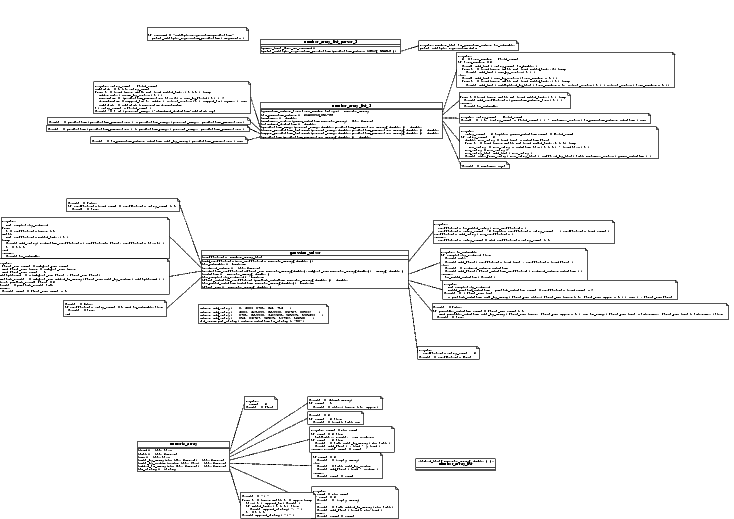
Design Review
If I was lax on cycle 1's design review, I was doubly so on cycle 2. Encouraged by the good test results from cycle 1, I had apparently forgotten that the code phase had taken twice as long as expected and generated twice as many errors! As a result, cycle 2 suffered from poor design-- most of which was fine, but cost me in test.
Code
Reused Code
All code from cycle 1 was reused, except for 4 lines of stub test code.
number_array_list_3
/*
*/
#ifndef NUMBER_ARRAY_LIST_3_H
#define NUMBER_ARRAY_LIST_3_H
#include <list>
#include <vector>
#include <string>
#ifndef SINGLE_VARIABLE_FUNCTION_H
#include "single_variable_function.h"
#endif
#ifndef NUMERIC_ARRAY_H
#include "numeric_array.h"
#endif
#ifndef GAUSSIAN_SOLVER_H
#include "gaussian_solver.h"
#endif
class number_array_list_3 : public std::list< numeric_array >
{
protected:
int m_field_count;
public:
int field_count( void ) const;
numeric_array head( void ) const;
number_array_list_3 tail( void ) const;
number_array_list_3 suffixed_by_item( const numeric_array& entry ) const;
number_array_list_3 suffixed_by_list( const number_array_list_3& rhs ) const;
number_array_list_3 mapped_to( int field_index, const single_variable_function& f ) const;
number_array_list_3 multiplied_by_list( int field_index, const number_array_list_3& rhs ) const;
number_array_list_3 sorted_by( int field_index ) const;
number_array_list_3 items_less_than( int field_index, double value ) const;
number_array_list_3 items_greater_than_or_equal_to( int field_index, double value ) const;
bool is_valid_entry( const numeric_array& entry ) const;
bool is_valid_field_index( int field_index ) const;
bool is_sorted_by( int field_index ) const;
double sum_by_field( int field_index ) const;
double mean_by_field( int field_index ) const;
int entry_count( void ) const;
void set_field_count( int new_field_count );
void add_entry( const numeric_array& entry );
void make_from_entry( const numeric_array& entry );
void make( void );
void make_from_list( const number_array_list_3& rhs );
number_array_list_3( void );
double standard_deviation( int field_index, bool is_full_population ) const;
double variance( int field_index, bool is_full_population ) const;
number_array_list_3 normalized_series( int field_index ) const;
int normalization_s_value( void ) const;
number_array_list_3 normalized_series_table( int field_index ) const;
number_array_list_3 normal_distribution_segments( int s ) const;
number_array_list_3 chi_squared_table( int field_index ) const;
double chi_squared_q( int field_index ) const;
double chi_squared_1_minus_p( int field_index ) const;
number_array_list_3 select_series( int field_index ) const;
int items_in_range( int field_index, double lower_limit, double upper_limit ) const;
std::string entry_as_string( const numeric_array& entry ) const;
std::string table_as_string( void ) const;
numeric_array gaussian_solver_term( int term_number ) const;
gaussian_solver to_gaussian_solver( void ) const;
double full_variance( void ) const;
number_array_list_3 full_variance_series( const numeric_array& gauss_solution ) const;
double full_standard_deviation( void ) const;
double prediction_range( double percent_range, const numeric_array& prediction_parameters ) const;
double lower_prediction_interval( double percent_range, const numeric_array& prediction_parameters ) const;
double upper_prediction_interval( double percent_range, const numeric_array& prediction_parameters ) const;
double prediction( const numeric_array& prediction_parameters ) const;
};
#endif
/*
*/ |
/*
*/
#include "number_array_list_3.h"
#ifndef CONTRACT_H
#include "contract.h"
#endif
#ifndef ADDER_H
#include "adder.h"
#endif
#ifndef SQUARE_H
#include "square.h"
#endif
#ifndef NORMAL_DISTRIBUTION_INVERSE_H
#include "normal_distribution_inverse.h"
#endif
#ifndef CHI_SQUARED_INTEGRAL_H
#include "chi_squared_integral.h"
#endif
#ifndef NORMALIZER_H
#include "normalizer.h"
#endif
#ifndef T_DISTRIBUTION_H
#include "t_distribution.h"
#endif
#include <math.h>
#include <stdio.h>
int
number_array_list_3::field_count( void ) const
{
return m_field_count;
}
numeric_array
number_array_list_3::head( void ) const
{
REQUIRE( entry_count() >= 1 );
return *(begin());
}
number_array_list_3
number_array_list_3::tail( void ) const
{
number_array_list_3 Result;
if ( entry_count() > 1 )
{
number_array_list_3::const_iterator tail_head = begin();
++tail_head;
Result.insert( Result.begin(), tail_head, end() );
Result.m_field_count = field_count();
ENSURE( Result.entry_count() == entry_count() - 1 );
}
return Result;
}
number_array_list_3
number_array_list_3::suffixed_by_item( const numeric_array& entry ) const
{
number_array_list_3 Result;
Result.make_from_list( *this );
Result.add_entry( entry );
ENSURE( Result.entry_count() == entry_count() + 1 );
return Result;
}
number_array_list_3
number_array_list_3::suffixed_by_list( const number_array_list_3& rhs ) const
{
number_array_list_3 Result;
Result.make_from_list( *this );
for ( number_array_list_3::const_iterator iter = rhs.begin(); iter != rhs.end(); ++iter )
{
Result.add_entry( *iter );
}
ENSURE( Result.entry_count() == entry_count() + rhs.entry_count() );
return Result;
}
number_array_list_3
number_array_list_3::mapped_to( int field_index, const single_variable_function& f ) const
{
REQUIRE( is_valid_field_index( field_index ) );
number_array_list_3 Result;
if ( entry_count() > 0 )
{
numeric_array new_entry = head();
new_entry[ field_index ] = f.at( head()[ field_index ] );
Result.make_from_list( Result.suffixed_by_item( new_entry ).suffixed_by_list( tail().mapped_to( field_index, f )));
}
ENSURE( Result.entry_count() == entry_count() );
return Result;
}
number_array_list_3
number_array_list_3::multiplied_by_list( int field_index, const number_array_list_3& rhs ) const
{
REQUIRE( entry_count() == rhs.entry_count() );
REQUIRE( field_count() == rhs.field_count() );
REQUIRE( is_valid_field_index( field_index ) );
number_array_list_3 Result;
if ( entry_count() > 0 )
{
numeric_array new_entry = head();
new_entry[ field_index ] = head()[ field_index ] * rhs.head()[field_index];
Result.make_from_list( Result.suffixed_by_item( new_entry ).
suffixed_by_list( tail().multiplied_by_list( field_index, rhs.tail() ) ) );
}
ENSURE( Result.entry_count() == entry_count() );
return Result;
}
number_array_list_3
number_array_list_3::sorted_by( int field_index ) const
{
REQUIRE( is_valid_field_index( field_index ) );
number_array_list_3 Result;
if ( is_sorted_by( field_index ) )
{
Result.make_from_list( *this );
}
else
{
Result.make_from_list( tail().items_less_than( field_index, head()[field_index] ).sorted_by( field_index ).
suffixed_by_item( head() ).
suffixed_by_list( tail().items_greater_than_or_equal_to( field_index, head()[field_index] ).sorted_by( field_index )));
}
ENSURE( Result.entry_count() == entry_count() );
return Result;
}
number_array_list_3
number_array_list_3::items_less_than( int field_index, double value ) const
{
REQUIRE( is_valid_field_index( field_index ) );
number_array_list_3 Result;
for ( number_array_list_3::const_iterator iter = begin(); iter != end(); ++iter )
{
if ( (*iter)[field_index] < value )
{
Result.add_entry( *iter );
}
}
ENSURE( Result.entry_count() <= entry_count() );
return Result;
}
number_array_list_3
number_array_list_3::items_greater_than_or_equal_to( int field_index, double value ) const
{
REQUIRE( is_valid_field_index( field_index ) );
number_array_list_3 Result;
for ( number_array_list_3::const_iterator iter = begin(); iter != end(); ++iter )
{
if ( (*iter)[field_index] >= value )
{
Result.add_entry(*iter);
}
}
ENSURE( Result.entry_count() <= entry_count() );
return Result;
}
bool
number_array_list_3::is_valid_entry( const numeric_array& entry ) const
{
bool Result = false;
if ( ( entry_count() == 0 )
|| ( ( entry_count() > 0 ) && ( entry.size() == field_count() ) ) )
{
Result = true;
}
return Result;
}
bool
number_array_list_3::is_valid_field_index( int field_index ) const
{
bool Result = true;
if ( entry_count() > 0 )
{
Result = ( 0 <= field_index ) && ( field_index < m_field_count );
}
return Result;
}
bool
number_array_list_3::is_sorted_by( int field_index ) const
{
REQUIRE( is_valid_field_index( field_index ) );
bool Result = true;
if ( entry_count() > 1 )
{
Result = ( head()[field_index] < tail().head()[field_index] ) && tail().is_sorted_by( field_index );
}
return Result;
}
double
number_array_list_3::sum_by_field( int field_index ) const
{
REQUIRE( is_valid_field_index( field_index ) )
double Result = 0;
if ( entry_count() > 0 )
{
Result = head()[field_index] + tail().sum_by_field( field_index );
}
return Result;
}
double
number_array_list_3::mean_by_field( int field_index ) const
{
REQUIRE( is_valid_field_index( field_index ) );
REQUIRE( entry_count() > 0 );
double Result = sum_by_field( field_index ) / static_cast<double>( entry_count() );
return Result;
}
int
number_array_list_3::entry_count( void ) const
{
return size();
}
void
number_array_list_3::set_field_count( int new_field_count )
{
REQUIRE( entry_count() == 0 );
m_field_count = new_field_count;
ENSURE( field_count() == new_field_count );
}
void
number_array_list_3::add_entry( const numeric_array& entry )
{
if ( entry_count() == 0 )
{
set_field_count( entry.size() );
}
REQUIRE( is_valid_entry( entry ) );
const int old_entry_count = entry_count();
push_back( entry );
ENSURE( entry_count() == old_entry_count + 1 );
}
void
number_array_list_3::make_from_entry( const numeric_array& entry )
{
make();
add_entry( entry );
ENSURE( entry_count() == 1 );
ENSURE( head() == entry );
}
void
number_array_list_3::make( void )
{
clear();
m_field_count = -1;
ENSURE( m_field_count == -1 );
ENSURE( entry_count() == 0 );
}
void
number_array_list_3::make_from_list( const number_array_list_3& rhs )
{
make();
insert( begin(), rhs.begin(), rhs.end() );
m_field_count = rhs.field_count();
ENSURE( entry_count() == rhs.entry_count() );
}
number_array_list_3::number_array_list_3( void )
{
make();
}
double
number_array_list_3::standard_deviation( int field_index, bool is_full_population ) const
{
double Result = sqrt( variance( field_index, is_full_population ) );
return Result;
}
double
number_array_list_3::variance( int field_index, bool is_full_population ) const
{
adder an_adder( -mean_by_field( field_index ) );
square a_square;
if ( is_full_population )
{
CHECK( entry_count() > 0 );
}
else
{
CHECK( entry_count() > 1 );
}
const double divisor = static_cast< double >( is_full_population ? entry_count() : entry_count() - 1 );
const double Result = mapped_to( field_index, an_adder ).
mapped_to( field_index, a_square ).sum_by_field( field_index ) / divisor;
return Result;
}
number_array_list_3
number_array_list_3::normalized_series( int field_index ) const
{
//cout << "Standard dev: " << standard_deviation( field_index, false ) << "\n";
normalizer a_normalizer( mean_by_field( field_index ), standard_deviation( field_index, false ) );
number_array_list_3 Result = mapped_to( field_index, a_normalizer ).select_series( field_index );
//cout << "**in normalized_series**\n" << mapped_to( field_index, a_normalizer ).table_as_string() << "\n";
ENSURE( Result.entry_count() == entry_count() );
//cout << "**normalized_series result**\n" << Result.table_as_string() << "\n";
return Result;
}
int
number_array_list_3::normalization_s_value( void ) const
{
REQUIRE( entry_count() % 5 == 0 );
int Result = entry_count() / 5;
return Result;
}
number_array_list_3
number_array_list_3::normalized_series_table( int field_index ) const
{
REQUIRE( entry_count() > 0 );
number_array_list_3 sorted_list;
sorted_list.make_from_list( sorted_by( field_index ) );
number_array_list_3 sorted_normalized_list = sorted_list.normalized_series( field_index );
//cout << "Sorted list: \n" << sorted_list.table_as_string() << "\n";
//cout << "sorted normalized_list: \n" << sorted_normalized_list.table_as_string() << "\n";
CHECK( sorted_list.entry_count() == entry_count() );
CHECK( sorted_normalized_list.entry_count() == entry_count() );
number_array_list_3::const_iterator sorted_list_iter;
number_array_list_3::const_iterator sorted_normalized_list_iter;
int i = 0;
number_array_list_3 Result;
for( i = 0, sorted_list_iter = sorted_list.begin(), sorted_normalized_list_iter = sorted_normalized_list.begin();
sorted_list_iter != sorted_list.end() && sorted_normalized_list_iter != sorted_normalized_list.end();
)//++i, ++sorted_list_iter, ++sorted_normalized_list_iter )
{
numeric_array new_entry;
new_entry.push_back( static_cast<double>(i + 1) );
new_entry.push_back( static_cast<double>(i + 1) / static_cast<double>(entry_count()));
new_entry.push_back( (*sorted_list_iter)[ field_index ] );
new_entry.push_back( (*sorted_normalized_list_iter)[ 0 ] );
Result.add_entry( new_entry );
++i;
++sorted_list_iter;
++sorted_normalized_list_iter;
}
ENSURE( Result.entry_count() == entry_count() );
return Result;
}
number_array_list_3
number_array_list_3::normal_distribution_segments( int s ) const
{
REQUIRE( s > 0 );
const double norm_floor = -10000;
const double norm_ceiling = 10000;
normal_distribution_inverse norm_inverse;
number_array_list_3 Result;
for ( int i = 1; i <= s; ++i )
{
numeric_array new_entry;
if ( i == 1 )
{
new_entry.push_back( norm_floor );
}
else
{
new_entry.push_back( norm_inverse.at( ( static_cast<double>(i - 1) )
* ( 1.0 / static_cast< double >( s ) )));
}
if ( i == s )
{
new_entry.push_back( norm_ceiling );
}
else
{
new_entry.push_back( norm_inverse.at( ( static_cast< double >( i ) )
* ( 1.0 / static_cast< double >( s ) )));
}
Result.add_entry( new_entry );
}
return Result;
}
number_array_list_3
number_array_list_3::chi_squared_table( int field_index ) const
{
number_array_list_3 normal_segments = normal_distribution_segments( normalization_s_value() );
number_array_list_3 norm_table = normalized_series_table( field_index );
number_array_list_3 Result;
square a_square;
//cout << "norm table\n" << norm_table.table_as_string() << "\n\n";
int i = 0;
number_array_list_3::const_iterator iter;
for ( i = 0, iter = normal_segments.begin(); iter != normal_segments.end(); ++iter, ++i )
{
numeric_array new_entry;
new_entry.push_back( i );
new_entry.push_back( (*iter)[0] );
new_entry.push_back( (*iter)[1] );
new_entry.push_back( static_cast< double >(norm_table.entry_count()) / norm_table.normalization_s_value() );
new_entry.push_back( static_cast< double >(norm_table.items_in_range( 3, new_entry[1], new_entry[2] ) ) );
new_entry.push_back( a_square.at( new_entry[3] - new_entry[4] ) );
new_entry.push_back( new_entry[5] / new_entry[ 3 ] );
Result.add_entry( new_entry );
}
return Result;
}
double
number_array_list_3::chi_squared_q( int field_index ) const
{
//cout << chi_squared_table( field_index ).table_as_string();
double Result = chi_squared_table( field_index ).sum_by_field( 6 );
return Result;
}
#ifndef CHI_SQUARED_BASE_H
#include "chi_squared_base.h"
#endif
double
number_array_list_3::chi_squared_1_minus_p( int field_index ) const
{
chi_squared_integral chi( normalization_s_value() - 1 );
double Result = 1 - chi.at( chi_squared_q( field_index ) );
return Result;
}
number_array_list_3
number_array_list_3::select_series( int field_index ) const
{
REQUIRE( is_valid_field_index( field_index ) );
number_array_list_3 Result;
if ( entry_count() > 0 )
{
numeric_array new_entry;
new_entry.push_back( head()[field_index] );
Result.add_entry( new_entry );
}
if ( entry_count() > 1 )
{
Result.make_from_list( Result.suffixed_by_list( tail().select_series( field_index ) ));
}
ENSURE( Result.entry_count() == entry_count() );
ENSURE( Result.field_count() == 1 );
return Result;
}
int
number_array_list_3::items_in_range( int field_index, double lower_limit, double upper_limit ) const
{
int Result = 0;
if (( entry_count() > 0 )
&& ( head()[field_index] > lower_limit )
&& ( head()[field_index] <= upper_limit ) )
{
Result = 1;
}
if ( entry_count() > 1 )
{
Result = Result + tail().items_in_range( field_index, lower_limit, upper_limit );
}
return Result;
}
std::string
number_array_list_3::entry_as_string( const numeric_array& entry ) const
{
return entry.to_string();
}
std::string
number_array_list_3::table_as_string( void ) const
{
std::string Result = "";
if ( entry_count() > 0 )
{
Result = Result + entry_as_string( head() ) + "\n";
}
if ( entry_count() > 1 )
{
Result = Result + tail().table_as_string();
}
return Result;
}
numeric_array
number_array_list_3::gaussian_solver_term( int term_number ) const
{
REQUIRE( 0 <= term_number < field_count() );
numeric_array Result;
if ( term_number == 0 )
{
Result.push_back( static_cast<double>(entry_count()) );
for ( int i = 0; i < field_count(); ++i )
{
Result.push_back( sum_by_field( i ) );
}
}
else
{
Result.push_back( sum_by_field( term_number - 1 ) );
number_array_list_3 term_series = select_series( term_number - 1 );
for ( int i = 0; i < field_count(); ++i )
{
Result.push_back( term_series.multiplied_by_list( 0, select_series( i ) ).sum_by_field( 0 ) );
}
}
ENSURE( Result.size() == field_count() + 1 );
return Result;
}
gaussian_solver
number_array_list_3::to_gaussian_solver( void ) const
{
gaussian_solver Result;
for ( int i = 0; i < field_count(); ++i )
{
Result.add_coefficients( gaussian_solver_term( i ) );
}
ENSURE( Result.is_solvable() );
return Result;
}
double
number_array_list_3::full_variance( void ) const
{
const double Result = ( 1.0 / ( static_cast<double>(entry_count()) - static_cast<double>( field_count() ) ) )
* full_variance_series( to_gaussian_solver().solution() ).sum_by_field( 0 );
return Result;
}
number_array_list_3
number_array_list_3::full_variance_series( const numeric_array& gauss_solution ) const
{
if ( entry_count() > 0 )
{
REQUIRE( gauss_solution.size() == field_count() );
}
number_array_list_3 Result;
if ( entry_count() > 0 )
{
double new_entry = head()[ head().size() - 1 ] - gauss_solution[ 0 ];
for ( int i = 0; i < field_count() - 1; ++i )
{
new_entry = new_entry - gauss_solution[ i + 1 ] * head()[ i ];
}
new_entry = new_entry*new_entry;
numeric_array new_entry_list;
new_entry_list.push_back( new_entry );
Result.make_from_entry( new_entry_list );
Result = Result.suffixed_by_list( tail().full_variance_series( gauss_solution ) );
}
ENSURE( Result.entry_count() == entry_count() );
return Result;
}
double
number_array_list_3::full_standard_deviation( void ) const
{
const double Result = sqrt( full_variance() );
return Result;
}
double
number_array_list_3::prediction_range( double percent_range, const numeric_array& prediction_parameters ) const
{
REQUIRE( entry_count() > field_count() );
double subtotal = 1.0 + 1.0 / static_cast<double>(entry_count() );
for ( int i = 0; i < field_count() - 1; ++i )
{
adder an_adder( -mean_by_field( i ) );
square a_square;
const double numerator = a_square.at( prediction_parameters[ i ] - mean_by_field( i ) );
const double denominator = mapped_to( i, an_adder ).mapped_to( i, a_square ).sum_by_field(i);
subtotal = subtotal + numerator / denominator;
}
t_distribution t;
t.set_n( entry_count() - field_count() );
const double Result = t.at( percent_range )*full_standard_deviation()*sqrt( subtotal );
return Result;
}
double
number_array_list_3::lower_prediction_interval( double percent_range, const numeric_array& prediction_parameters ) const
{
const double Result = prediction( prediction_parameters ) - prediction_range( percent_range, prediction_parameters );
return Result;
}
double
number_array_list_3::upper_prediction_interval( double percent_range, const numeric_array& prediction_parameters ) const
{
const double Result = prediction( prediction_parameters ) + prediction_range( percent_range, prediction_parameters );
return Result;
}
double
number_array_list_3::prediction( const numeric_array& prediction_parameters ) const
{
const double Result = to_gaussian_solver().solution().head() +
to_gaussian_solver().solution().tail().mult_by_array( prediction_parameters ).sum();
return Result;
}
/*
*/ |
class NUMBER_ARRAY_LIST_3
inherit
LINKED_LIST[NUMERIC_ARRAY]
redefine make
end;
creation {ANY}
make, make_from_entry, make_from_list
feature {ANY}
field_count: INTEGER;
--number of fields allowed in an entry
head: like item is
--first item
require
entry_count >= 1;
do
Result := first;
end -- head
tail: like Current is
--all items after the first
do
!!Result.make;
if entry_count > 1 then
Result := slice(lower + 1,upper);
Result.set_field_count(field_count);
end;
ensure
entry_count > 1 implies Result.entry_count = entry_count - 1 and Result.field_count = field_count;
end -- tail
suffixed_by_list(rhs: like Current): like Current is
--the list, suffixed by another list
local
i: INTEGER;
do
!!Result.make_from_list(Current);
from
i := rhs.lower;
until
not rhs.valid_index(i)
loop
Result.add_entry(rhs.item(i));
i := i + 1;
end;
ensure
Result.entry_count = entry_count + rhs.entry_count;
end -- suffixed_by_list
make_from_entry(entry: like item) is
--clear the list, then add the entry
do
make;
add_entry(entry);
ensure
head.is_equal(entry);
field_count = entry.count;
end -- make_from_entry
make is
--clear the list
do
Precursor;
field_count := - 1;
ensure
entry_count = 0;
field_count = - 1;
end -- make
make_from_list(rhs: like Current) is
--clear the list, setting it equal to another list
do
from_collection(rhs);
field_count := rhs.field_count;
end -- make_from_list
sum_by_field(field_index: INTEGER): DOUBLE is
--the sum of a given field over all entries
require
is_valid_field_index(field_index);
do
if entry_count = 0 then
Result := 0;
else
Result := head.item(field_index) + tail.sum_by_field(field_index);
end;
end -- sum_by_field
mean_by_field(field_index: INTEGER): DOUBLE is
--the mean of a given field over all entries
require
is_valid_field_index(field_index);
entry_count >= 1;
do
Result := sum_by_field(field_index) / entry_count.to_double;
end -- mean_by_field
entry_count: INTEGER is
--the number of entries
do
Result := count;
end -- entry_count
add_entry(new_entry: like item) is
-- adds an entry to the end of the list
require
is_valid_entry(new_entry);
do
if entry_count = 0 then
set_field_count(new_entry.count);
end;
add_last(new_entry);
ensure
entry_count = old entry_count + 1;
end -- add_entry
mapped_to(field_index: INTEGER; f: SINGLE_VARIABLE_FUNCTION): like Current is
--the elements, with the given field mapped to f
require
is_valid_field_index(field_index);
local
new_entry: like item;
do
!!Result.make;
if entry_count > 0 then
new_entry := head.twin;
new_entry.put(f.at(head.item(field_index)),field_index);
Result.add_entry(new_entry);
Result := Result.suffixed_by_list(tail.mapped_to(field_index,f));
end;
ensure
Result.entry_count = entry_count;
end -- mapped_to
multiplied_by_list(field_index: INTEGER; rhs: like Current): like Current is
--the elements, with the given field multiplied by the
--corresponding field in rhs
require
entry_count = rhs.entry_count;
field_count = rhs.field_count;
is_valid_field_index(field_index);
local
new_entry: like item;
do
!!Result.make;
if entry_count > 0 then
new_entry := head;
new_entry.put(head.item(field_index) * rhs.head.item(field_index),field_index);
Result.add_entry(new_entry);
Result := Result.suffixed_by_list(tail.multiplied_by_list(field_index,rhs.tail));
end;
ensure
Result.entry_count = entry_count;
end -- multiplied_by_list
sorted_by(field_index: INTEGER): like Current is
--the list, sorted by the given field
require
is_valid_field_index(field_index);
do
if is_sorted_by(field_index) then
!!Result.make_from_list(Current);
else
!!Result.make_from_list(tail.items_less_than(field_index,head.item(field_index)).sorted_by(field_index).suffixed_by_item(head).suffixed_by_list(tail.items_greater_than_or_equal_to(field_index,head.item(field_index)).sorted_by(field_index)));
end;
ensure
Result.entry_count = entry_count;
end -- sorted_by
is_valid_entry(entry: like item): BOOLEAN is
--whether entry is a valid entry
do
if entry_count = 0 and entry.count > 0 or entry.count = field_count and entry.lower = 1 then
Result := true;
else
Result := false;
end;
end -- is_valid_entry
items_less_than(field_index: INTEGER; value: DOUBLE): like Current is
--list of items less than the given value in the given field
require
is_valid_field_index(field_index);
local
i: INTEGER;
do
!!Result.make;
from
i := lower;
until
not valid_index(i)
loop
if not (item(i).item(field_index) >= value) then
Result.add_entry(item(i));
end;
i := i + 1;
end;
ensure
Result.entry_count <= entry_count;
end -- items_less_than
items_greater_than_or_equal_to(field_index: INTEGER; value: DOUBLE): like Current is
--list of items greater than or equal to the given value in the
--given field
require
is_valid_field_index(field_index);
local
i: INTEGER;
do
!!Result.make;
from
i := lower;
until
not valid_index(i)
loop
if item(i).item(field_index) >= value then
Result.add_entry(item(i));
end;
i := i + 1;
end;
ensure
Result.entry_count <= entry_count;
end -- items_greater_than_or_equal_to
suffixed_by_item(entry: like item): like Current is
--the list, suffixed by a single item
require
is_valid_entry(entry);
do
!!Result.make_from_list(Current);
Result.add_entry(entry);
ensure
Result.entry_count = entry_count + 1;
end -- suffixed_by_item
set_field_count(new_field_count: INTEGER) is
--sets the field count
require
entry_count = 0 or (entry_count > 0 implies head.count = new_field_count);
do
field_count := new_field_count;
ensure
field_count = new_field_count;
end -- set_field_count
is_valid_field_index(field_index: INTEGER): BOOLEAN is
--whether the given field index is valid
do
if entry_count = 0 then
Result := true;
else
Result := 1 <= field_index and field_index <= field_count;
end;
end -- is_valid_field_index
is_sorted_by(field_index: INTEGER): BOOLEAN is
--whether the list is sorted by the given field index
require
is_valid_field_index(field_index);
do
Result := true;
if entry_count > 1 then
Result := head.item(field_index) < tail.head.item(field_index) and tail.is_sorted_by(field_index);
end;
end -- is_sorted_by
feature {ANY} --chi-squared distribution calcs
variance(field_index: INTEGER; is_full_population: BOOLEAN): DOUBLE is
require
is_valid_field_index(field_index);
is_full_population implies entry_count > 0;
not is_full_population implies entry_count > 1;
local
divisor: DOUBLE;
adder: ADDER;
square: SQUARE;
do
if is_full_population then
divisor := entry_count.to_double;
else
divisor := (entry_count - 1).to_double;
end;
!!adder.make(- mean_by_field(field_index));
!!square;
Result := mapped_to(field_index,adder).mapped_to(field_index,square).sum_by_field(field_index) / divisor;
end -- variance
standard_deviation(field_index: INTEGER; is_full_population: BOOLEAN): DOUBLE is
require
is_valid_field_index(field_index);
do
Result := variance(field_index,is_full_population).sqrt;
end -- standard_deviation
normalized_series(field_index: INTEGER): like Current is
--one series of the table, "normalized" into standard deviations
require
is_valid_field_index(field_index);
local
normalizer: NORMALIZER;
do
!!normalizer.make(mean_by_field(field_index),standard_deviation(field_index,false));
Result := mapped_to(field_index,normalizer).select_series(field_index);
ensure
Result.entry_count = entry_count;
end -- normalized_series
normalization_s_value: INTEGER is
--number of segments in a normalization table
require
entry_count.divisible(5);
do
Result := entry_count // 5;
end -- normalization_s_value
normalized_series_table(field_index: INTEGER): like Current is
--a normalized series table, used for error-checking and used
--in the chi-squared normalization test
require
entry_count > 0;
is_valid_field_index(field_index);
local
sorted_list: like Current;
sorted_normalized_list: like Current;
i: INTEGER;
new_entry: NUMERIC_ARRAY;
do
sorted_list := sorted_by(field_index);
sorted_normalized_list := sorted_list.normalized_series(field_index);
check
sorted_list.entry_count = entry_count;
sorted_normalized_list.entry_count = entry_count;
end;
from
i := sorted_list.lower;
!!Result.make;
until
not sorted_list.valid_index(i)
loop
!!new_entry.make_empty;
new_entry.add_last(i.to_double);
new_entry.add_last(i.to_double / entry_count.to_double);
new_entry.add_last(sorted_list.item(i).item(field_index));
new_entry.add_last(sorted_normalized_list.item(i).first);
Result.add_entry(new_entry);
i := i + 1;
end;
end -- normalized_series_table
normal_distribution_segments(s: INTEGER): like Current is
--segments of the normal distribution; see [Humphrey95] for use
require
s > 0;
local
i: INTEGER;
new_entry: NUMERIC_ARRAY;
norm_inverse: NORMAL_DISTRIBUTION_INVERSE;
do
from
i := 1;
!!Result.make;
!!norm_inverse;
until
i > s
loop
!!new_entry.make_empty;
if i = 1 then
new_entry.add_last(- 1000.0);
else
new_entry.add_last(norm_inverse.at((i - 1).to_double * (1.0 / s.to_double)));
end;
if i = s then
new_entry.add_last(1000.0);
else
new_entry.add_last(norm_inverse.at(i.to_double * 1.0 / s.to_double));
end;
Result.add_entry(new_entry);
i := i + 1;
end;
end -- normal_distribution_segments
chi_squared_table(field_index: INTEGER): like Current is
-- chi-squared table, used to calculate the chi-squared distribution
require
is_valid_field_index(field_index);
local
norm_segments: like Current;
norm_table: like Current;
i: INTEGER;
new_entry: NUMERIC_ARRAY;
do
from
norm_segments := normal_distribution_segments(normalization_s_value);
norm_table := normalized_series_table(field_index);
!!Result.make;
i := norm_segments.lower;
until
not norm_segments.valid_index(i)
loop
!!new_entry.make_empty;
new_entry.add_last(i.to_double);
new_entry.add_last(norm_segments.item(i).item(1));
new_entry.add_last(norm_segments.item(i).item(2));
new_entry.add_last(norm_table.entry_count.to_double / norm_table.normalization_s_value.to_double);
new_entry.add_last(norm_table.items_in_range(4,new_entry.item(2),new_entry.item(3)));
new_entry.add_last((new_entry.item(4) - new_entry.item(5)) ^ 2);
new_entry.add_last(new_entry.item(6) / new_entry.item(4));
Result.add_entry(new_entry);
i := i + 1;
end;
end -- chi_squared_table
chi_squared_q(field_index: INTEGER): DOUBLE is
--"Q" value of chi-squared normalization test
do
Result := chi_squared_table(field_index).sum_by_field(7);
end -- chi_squared_q
chi_squared_1_minus_p(field_index: INTEGER): DOUBLE is
--1-p value of chi-squared normalization test
local
chi_squared_integral: CHI_SQUARED_INTEGRAL;
do
!!chi_squared_integral.make(normalization_s_value - 1);
Result := 1 - chi_squared_integral.at(chi_squared_q(field_index));
end -- chi_squared_1_minus_p
select_series(field_index: INTEGER): like Current is
--the given series, extracted as a separate list
require
is_valid_field_index(field_index);
local
new_entry: NUMERIC_ARRAY;
do
if entry_count = 0 then
!!Result.make;
else
!!new_entry.make_empty;
new_entry.add_last(head.item(field_index));
!!Result.make_from_entry(new_entry);
if entry_count > 1 then
Result := Result.suffixed_by_list(tail.select_series(field_index));
end;
end;
end -- select_series
items_in_range(field_index: INTEGER; lower_limit, upper_limit: DOUBLE): INTEGER is
--the items from the given field which fit in (lower limit < item <= upper_limit)
require
is_valid_field_index(field_index);
do
if entry_count > 0 and head.item(field_index) > lower_limit and upper_limit >= head.item(field_index) then
Result := 1;
end;
if entry_count > 1 then
Result := Result + tail.items_in_range(field_index,lower_limit,upper_limit);
end;
end -- items_in_range
entry_as_string(entry: like item): STRING is
--entry as a string, ie "( 1, 2, 3 )"
do
Result := entry.to_string;
end -- entry_as_string
table_as_string: STRING is
--table, as a set of entry_as_string lines
do
if entry_count > 0 then
Result := entry_as_string(head) + "%N";
if entry_count > 1 then
Result.append_string(tail.table_as_string);
end;
end;
end -- table_as_string
feature {ANY} -- multiple regression features
gaussian_solver_term(term_number: INTEGER): NUMERIC_ARRAY is
--term for gaussian solver to solve for multiple regression parameters
require
1 <= term_number and term_number < field_count + 1;
local
i: INTEGER;
do
!!Result.make_empty;
if term_number = 1 then
Result.add_last(entry_count.to_double);
from
i := head.lower;
until
not head.valid_index(i)
loop
Result.add_last(sum_by_field(i));
i := i + 1;
end;
else
Result.add_last(sum_by_field(term_number - 1));
from
i := head.lower;
until
not head.valid_index(i)
loop
Result.add_last(select_series(term_number - 1).multiplied_by_list(1,select_series(i)).sum_by_field(1));
i := i + 1;
end;
end;
end -- gaussian_solver_term
to_gaussian_solver: GAUSSIAN_SOLVER is
--creates a gaussian solver for the multiple regression parameters
local
i: INTEGER;
do
!!Result.make;
from
i := head.lower;
until
not head.valid_index(i)
loop
Result.add_coefficients(gaussian_solver_term(i));
i := i + 1;
end;
ensure
Result.is_solvable;
end -- to_gaussian_solver
full_variance: DOUBLE is
--total variance of the data set
require
entry_count > field_count;
do
Result := ( 1.0 / (entry_count.to_double - field_count.to_double) ) * full_variance_series(to_gaussian_solver.solution).sum_by_field(1);
end -- full_variance
full_variance_series(gauss_solution: NUMERIC_ARRAY): like Current is
--variance series, used to calculate the variance
require
entry_count > 0 implies gauss_solution.count = field_count;
local
i: INTEGER;
new_entry: DOUBLE;
new_entry_list: NUMERIC_ARRAY;
do
if entry_count = 0 then
!!Result.make
else
new_entry := head.last - gauss_solution.first;
from
i := head.lower;
until
not head.valid_index(i + 1)
loop
new_entry := new_entry - gauss_solution.item(i + 1) * head.item(i);
i := i + 1;
end;
new_entry := new_entry ^ 2;
!!new_entry_list.make_empty;
new_entry_list.add_last(new_entry);
!!Result.make_from_entry(new_entry_list);
Result := Result.suffixed_by_list(tail.full_variance_series(gauss_solution));
end
end -- full_variance_series
full_standard_deviation: DOUBLE is
--standard deviation of the data set
do
Result := full_variance.sqrt;
end -- full_standard_deviation
prediction_range(percent_range: DOUBLE; prediction_parameters: NUMERIC_ARRAY): DOUBLE is
--prediction range for the given prediction and percent
require
entry_count > field_count;
local
i: INTEGER;
numerator: DOUBLE;
denominator: DOUBLE;
subtotal: DOUBLE;
adder: ADDER;
square: SQUARE;
t: T_DISTRIBUTION;
do
subtotal := 1.0 + 1.0 / entry_count.to_double;
from
i := head.lower;
until
not head.valid_index(i + 1)
loop
!!adder.make(- mean_by_field(i));
!!square
numerator := adder.at(prediction_parameters.item(i)) ^ 2;
denominator := mapped_to(i,adder).select_series(i).mapped_to(1,square).sum_by_field(1);
subtotal := subtotal + numerator / denominator;
i := i + 1;
end;
!!t.make;
t.set_n(entry_count - field_count);
Result := t.at(percent_range) * full_standard_deviation * subtotal.sqrt;
end -- prediction_range
lower_prediction_interval(percent_range: DOUBLE; parameters: NUMERIC_ARRAY): DOUBLE is
--LPI for percent range and prediction
do
Result := prediction(parameters) - prediction_range(percent_range,parameters);
end -- lower_prediction_interval
upper_prediction_interval(percent_range: DOUBLE; parameters: NUMERIC_ARRAY): DOUBLE is
--UPI for percent range and distribution
do
Result := prediction(parameters) + prediction_range(percent_range,parameters);
end -- upper_prediction_interval
prediction(parameters: NUMERIC_ARRAY): DOUBLE is
--prediction using multiple regression given the parameters by series
do
Result := to_gaussian_solver.solution.head + to_gaussian_solver.solution.tail.mult_by_array(parameters).sum;
end -- prediction
end -- class NUMBER_ARRAY_LIST_3 |
number_array_list_parser_3
#ifndef NUMBER_ARRAY_LIST_PARSER_3_H
#define NUMBER_ARRAY_LIST_PARSER_3_H
#ifndef SIMPLE_INPUT_PARSER_H
#include "simple_input_parser.h"
#endif
#ifndef NUMBER_ARRAY_LIST_3_H
#include "number_array_list_3.h"
#endif
class number_array_list_parser_3: public simple_input_parser
{
protected:
number_array_list_3 number_list;
enum state_t { Parsing_historical_data, Parsing_commands };
state_t state;
public:
virtual std::string transformed_line (const std::string & line) const;
std::string string_stripped_of_comments (const std::string & str) const;
static bool is_double (const std::string & str);
static double double_from_string (const std::string & str);
static const std::string & historical_data_terminator;
static const std::string & inline_comment_begin;
bool last_line_is_blank (void);
virtual void parse_last_line (void);
void parse_last_line_as_historical_data (void);
void parse_last_line_as_end_of_historical_data (void);
void parse_last_line_as_command( void );
void print_normalization_check( int field_index ) const;
void print_multiple_regression_prediction( const numeric_array& parameters ) const;
void make( void );
number_array_list_parser_3( void );
bool last_line_is_valid_historical_data( void ) const;
static std::vector< std::string > split_string( const std::string& string_to_split, const std::string& separator );
static std::string string_before_separator( const std::string& string_to_split, const std::string& separator );
static std::string string_after_separator( const std::string& string_to_split, const std::string& separator );
static numeric_array numbers_from_string( const std::string& string_to_split );
};
#endif |
/*
*/
#include "number_array_list_parser_3.h"
#ifndef WHITESPACE_STRIPPER_H
#include "whitespace_stripper.h"
#endif
#ifndef ERROR_LOG_H
#include "error_log.h"
#endif
#ifndef CONTRACT_H
#include "contract.h"
#endif
void
number_array_list_parser_3::make (void)
{
simple_input_parser::reset ();
state = Parsing_historical_data;
number_list.make ();
}
std::string number_array_list_parser_3::transformed_line (const std::string & str) const
{
return whitespace_stripper::string_stripped_of_whitespace (string_stripped_of_comments (str));
}
std::string
number_array_list_parser_3::string_stripped_of_comments (const std::string & str) const
{
const std::string::size_type comment_index = str.find (inline_comment_begin);
return str.substr (0, comment_index);
}
bool
number_array_list_parser_3::is_double (const std::string & str)
{
bool
Result = true;
char *
conversion_end = NULL;
strtod (str.c_str (), &conversion_end);
if (conversion_end == str.data ())
{
Result = false;
}
return Result;
}
double
number_array_list_parser_3::double_from_string (const std::string & str)
{
REQUIRE (is_double (str));
return strtod (str.c_str (), NULL);
}
const
std::string & number_array_list_parser_3::historical_data_terminator = "stop";
const
std::string & number_array_list_parser_3::inline_comment_begin = "--";
bool number_array_list_parser_3::last_line_is_blank (void)
{
if (last_line ().length () == 0)
{
return true;
}
else
{
return false;
}
}
void
number_array_list_parser_3::parse_last_line (void)
{
if (last_line_is_blank ())
{
return;
}
if ( state == Parsing_historical_data )
{
if ( last_line () == historical_data_terminator)
{
parse_last_line_as_end_of_historical_data ();
}
else
{
parse_last_line_as_historical_data ();
}
}
else
{
parse_last_line_as_command();
}
}
void
number_array_list_parser_3::parse_last_line_as_historical_data (void)
{
if ( last_line_is_valid_historical_data() )
{
const numeric_array this_entry = numbers_from_string( last_line() );
number_list.add_entry( this_entry );
}
else
{
error_log errlog;
errlog.log_error( std::string( "Invalid data entry: " ) + last_line() );
}
}
void
number_array_list_parser_3::parse_last_line_as_end_of_historical_data (void)
{
REQUIRE (last_line () == historical_data_terminator);
cout << "Historical data read; "
<< number_list.entry_count() << " entries, "
<< number_list.field_count() << " fields.\n";
state = Parsing_commands;
}
number_array_list_parser_3::number_array_list_parser_3 (void)
{
make();
}
bool
number_array_list_parser_3::last_line_is_valid_historical_data( void ) const
{
const std::vector< std::string > substrings = split_string( last_line(), "," );
bool Result = true;
//make sure we have a valid field count for the number_array_list
if ( ( number_list.entry_count() > 0 ) && ( substrings.size() != number_list.field_count() ) )
{
Result = false;
}
//...and that each substring can be interpreted as a double
for ( int i = 0; i < substrings.size(); ++i )
{
if ( !is_double( substrings[ i ] ) )
{
Result = false;
}
}
return Result;
}
std::vector< std::string >
number_array_list_parser_3::split_string( const std::string& string_to_split, const std::string& separator )
{
std::vector< std::string > Result;
const std::string prefix = string_before_separator( string_to_split, separator );
const std::string remainder = string_after_separator( string_to_split, separator );
Result.push_back( prefix );
if ( remainder.size() > 0 )
{
const std::vector< std::string > split_remainder = split_string( remainder, separator );
Result.insert( Result.end(), split_remainder.begin(), split_remainder.end() );
}
return Result;
}
std::string
number_array_list_parser_3::string_before_separator( const std::string& string_to_split, const std::string& separator )
{
const std::string::size_type separator_position = string_to_split.find( separator );
std::string Result;
if ( separator_position == string_to_split.npos )
{
//not found; result is entire string
Result = string_to_split;
}
else
{
Result = string_to_split.substr( 0, separator_position );
}
return Result;
}
std::string
number_array_list_parser_3::string_after_separator( const std::string& string_to_split, const std::string& separator )
{
const std::string::size_type separator_position = string_to_split.find( separator );
std::string Result;
if ( separator_position == string_to_split.npos )
{
//not found; result is empty
Result = "";
}
else
{
Result = string_to_split.substr( separator_position + separator.size(), string_to_split.size() );
}
return Result;
}
numeric_array
number_array_list_parser_3::numbers_from_string( const std::string& string_to_split )
{
const std::vector< std::string > number_strings = split_string( string_to_split, "," );
numeric_array Result;
for ( std::vector< std::string >::const_iterator iter = number_strings.begin(); iter != number_strings.end(); ++iter )
{
CHECK( is_double( *iter ) );
const double new_value = double_from_string( *iter );
Result.push_back( new_value );
}
return Result;
}
void
number_array_list_parser_3::parse_last_line_as_command( void )
{
const std::string command = string_before_separator( last_line(), " " );
const std::string argument_string = string_after_separator( last_line(), " " );
std::vector< string > arguments = split_string( argument_string, " " );
if ( command == "normality_check_on_series" )
{
print_normalization_check( static_cast< int >( double_from_string( arguments[0] ) ) );
}
else if ( command == "multiple-regression-prediction" )
{
print_multiple_regression_prediction( numbers_from_string( argument_string ) );
}
else
{
cout << "unknown command: " << last_line() << "\n";
}
}
void
number_array_list_parser_3::print_normalization_check( int field_index ) const
{
cout << "Normalization check on series: " << field_index << "\n";
cout << "Q: " << number_list.chi_squared_q( field_index ) << "\n";
cout << "(1-p): " << number_list.chi_squared_1_minus_p( field_index ) << "\n";
}
void
number_array_list_parser_3::print_multiple_regression_prediction( const numeric_array& parameters ) const
{
if ( number_list.entry_count() <= number_list.field_count() )
{
cout << "Too few entries for multiple regression prediction!\n";
}
else if ( parameters.size() != number_list.field_count() - 1 )
{
cout << "Incorrect number of parameters for multiple regression; expected "
<< number_list.field_count() - 1 << ", got " << parameters.size() << "\n";
}
else
{
cout << "Multiple regression prediction: \n";
cout << "Solution: " << number_list.to_gaussian_solver().solution().to_string() << "\n";
cout << "Variance: " << number_list.full_variance() << "\n";
cout << "Standard Deviation: " << number_list.full_standard_deviation() << "\n\n";
cout << "Prediction from values: " << parameters.to_string() << "\n";
cout << "Projected result: " << number_list.prediction( parameters ) << "\n";
cout << "UPI( 70% ): " << number_list.upper_prediction_interval( 0.7, parameters ) << "\n";
cout << "LPI( 70% ): " << number_list.lower_prediction_interval( 0.7, parameters ) << "\n";
cout << "UPI( 90% ): " << number_list.upper_prediction_interval( 0.9, parameters ) << "\n";
cout << "LPI( 90% ): " << number_list.lower_prediction_interval( 0.9, parameters ) << "\n";
}
}
/*
*/ |
class NUMBER_ARRAY_LIST_PARSER_3
--reads a list of number pairs, and performs linear regression analysis
inherit
SIMPLE_INPUT_PARSER
redefine parse_last_line, transformed_line
end;
creation {ANY}
make
feature {ANY}
inline_comment_begin: STRING is "--";
string_stripped_of_comment(string: STRING): STRING is
--strip the string of any comment
local
comment_index: INTEGER;
do
if string.has_string(inline_comment_begin) then
comment_index := string.index_of_string(inline_comment_begin);
if comment_index = 1 then
!!Result.make_from_string("");
else
Result := string.substring(1,comment_index - 1);
end;
else
Result := string.twin;
end;
end -- string_stripped_of_comment
string_stripped_of_whitespace(string: STRING): STRING is
--strip string of whitespace
do
Result := string.twin;
Result.left_adjust;
Result.right_adjust;
end -- string_stripped_of_whitespace
transformed_line(string: STRING): STRING is
--strip comments and whitespace from parseable line
do
Result := string_stripped_of_whitespace(string_stripped_of_comment(string));
end -- transformed_line
number_list: NUMBER_ARRAY_LIST_3;
state: INTEGER;
Parsing_historical_data: INTEGER is unique;
Parsing_commands: INTEGER is unique;
Command_normality_check_on_series: STRING is
once
Result := "normality_check_on_series";
end -- Command_normality_check_on_series
Command_multiple_regression_prediction: STRING is
once
Result := "multiple-regression-prediction";
end -- Command_multiple_regression_prediction
historical_data_terminator: STRING is "stop";
double_from_string(string: STRING): DOUBLE is
require
string.is_double or string.is_integer;
do
if string.is_double then
Result := string.to_double;
elseif string.is_integer then
Result := string.to_integer.to_double;
end;
end -- double_from_string
feature {ANY} --parsing
reset is
--resets the parser and makes it ready to go again
do
state := Parsing_historical_data;
number_list.make;
end -- reset
make is
do
!!number_list.make;
reset;
end -- make
parse_last_line_as_historical_data is
--interpret last_line as a pair of comma-separated values
local
error_log: ERROR_LOG;
this_line_numbers: NUMERIC_ARRAY;
do
!!error_log.make;
if last_line_is_valid_historical_data then
this_line_numbers := numbers_from_string(last_line);
number_list.add_entry(this_line_numbers);
else
error_log.log_error("Invalid historical data: " + last_line + "%N");
end;
end -- parse_last_line_as_historical_data
parse_last_line_as_end_of_historical_data is
--interpret last line as the end of historical data
require
last_line.compare(historical_data_terminator) = 0;
local
i: INTEGER;
do
state := Parsing_commands;
std_output.put_string("Historical data read; " + number_list.entry_count.to_string + "items read%N");
end -- parse_last_line_as_end_of_historical_data
parse_last_line_as_command is
--interpret the last line as a command
local
command: STRING;
argument_string: STRING;
arguments: ARRAY[STRING];
do
command := string_before_separator(last_line," ");
argument_string := string_after_separator(last_line," ");
arguments := split_string(argument_string," ");
if command.is_equal(Command_normality_check_on_series) then
print_normalization_check_on_series(arguments.first.to_integer + 1);
elseif command.is_equal(Command_multiple_regression_prediction) then
print_multiple_regression_prediction(numbers_from_string(argument_string));
else
std_output.put_string("Unrecognized command string: " + last_line);
end;
end -- parse_last_line_as_command
parse_last_line is
--parse the last line according to state
do
if not last_line.empty then
if state = Parsing_historical_data then
if last_line.compare(historical_data_terminator) = 0 then
parse_last_line_as_end_of_historical_data;
else
parse_last_line_as_historical_data;
end;
else
parse_last_line_as_command;
end;
end;
end -- parse_last_line
last_line_is_valid_historical_data: BOOLEAN is
--whether last line is valid historical data
local
substrings: ARRAY[STRING];
i: INTEGER;
do
substrings := split_string(last_line,",");
Result := true;
if number_list.entry_count > 0 and substrings.count /= number_list.field_count then
Result := false;
end;
from
i := substrings.lower;
until
not substrings.valid_index(i)
loop
if not (substrings.item(i).is_double or substrings.item(i).is_integer) then
Result := false;
end;
i := i + 1;
end;
end -- last_line_is_valid_historical_data
split_string(string_to_split, separator: STRING): ARRAY[STRING] is
--a list of components of a string, separated by the given
--separator, ie split_string( "1,2,3", "," ) = [ "1", "2", "3" ]
local
prior_to_separator: STRING;
remainder: STRING;
split_remainder: ARRAY[STRING];
i: INTEGER;
do
prior_to_separator := string_before_separator(string_to_split,separator);
remainder := string_after_separator(string_to_split,separator);
!!Result.make(1,0);
Result.add_last(prior_to_separator);
if remainder.count > 0 then
split_remainder := split_string(remainder,separator);
from
i := split_remainder.lower;
until
not split_remainder.valid_index(i)
loop
Result.add_last(split_remainder.item(i));
i := i + 1;
end;
end;
end -- split_string
string_before_separator(string_to_split, separator: STRING): STRING is
--the part of a string which comes before the separator, or
--the whole string if it's not found
local
separator_index: INTEGER;
do
separator_index := string_to_split.substring_index(separator,1);
if separator_index = 0 then
--not found; copy whole string
Result := string_to_split.twin;
else
Result := string_to_split.substring(1,separator_index - 1);
end;
end -- string_before_separator
string_after_separator(string_to_split, separator: STRING): STRING is
--the part of the string after the separator,
local
separator_index: INTEGER;
do
separator_index := string_to_split.substring_index(separator,1);
if separator_index = 0 then
--not found; result is empty
!!Result.make_from_string("");
else
Result := string_to_split.substring(separator_index + separator.count,string_to_split.count);
end;
end -- string_after_separator
numbers_from_string(string_to_split: STRING): NUMERIC_ARRAY is
--an array of numbers, from a string of numbers separated by commas
local
number_strings: ARRAY[STRING];
i: INTEGER;
do
!!Result.make_empty;
number_strings := split_string(string_to_split,",");
from
i := number_strings.lower;
until
not number_strings.valid_index(i)
loop
check
number_strings.item(i).is_double or number_strings.item(i).is_integer;
end;
Result.add_last(double_from_string(number_strings.item(i)));
i := i + 1;
end;
end -- numbers_from_string
print_normalization_check_on_series(field_index: INTEGER) is
do
std_output.put_string("Normalization check on series ");
std_output.put_integer(field_index);
--std_error.put_string( number_list.sorted_by( field_index ).table_as_string + "%N" )
--std_error.put_string( number_list.normalized_series_table( field_index ).table_as_string )
std_output.put_string("%NQ: ");
std_output.put_double(number_list.chi_squared_q(field_index));
std_output.put_string("%N(1-p): ");
std_output.put_double(number_list.chi_squared_1_minus_p(field_index));
std_output.put_new_line;
end -- print_normalization_check_on_series
print_multiple_regression_prediction(parameters: NUMERIC_ARRAY) is
--print a multiple regression prediction, including all beta
--values and prediction ranges
do
if number_list.entry_count <= number_list.field_count then
std_output.put_string("Too few entries for multiple regression prediction%N");
elseif parameters.count /= number_list.field_count - 1 then
std_output.put_string("Incorrect number of parameters for multiple regression. ");
std_output.put_string("Expected " + (number_list.field_count - 1).to_string + ", got " + parameters.count.to_string + "%N");
else
std_output.put_string("Multiple regression prediction.%N");
std_output.put_string("Solution: " + number_list.to_gaussian_solver.solution.to_string + "%N");
std_output.put_string("Variance: " + number_list.full_variance.to_string + "%N");
std_output.put_string("Standard Deviation: " + number_list.full_standard_deviation.to_string + "%N");
std_output.put_string("Prediction from values: " + parameters.to_string + "%N");
std_output.put_string("Projected result: " + number_list.prediction(parameters).to_string + "%N");
std_output.put_string("UPI( 70%% ): " + number_list.upper_prediction_interval(0.7,parameters).to_string + "%N");
std_output.put_string("LPI( 70%% ): " + number_list.lower_prediction_interval(0.7,parameters).to_string + "%N");
std_output.put_string("UPI( 90%% ): " + number_list.upper_prediction_interval(0.9,parameters).to_string + "%N");
std_output.put_string("LPI( 90%% ): " + number_list.lower_prediction_interval(0.9,parameters).to_string + "%N");
end;
end -- print_multiple_regression_prediction
end -- class NUMBER_ARRAY_LIST_PARSER_3 |
Code Review
Again, sloppy processes; I let several easy ones get past me (including several instances of my personal bugaboo, forgetting parentheses on zero-argument features). Embarassing.
Compile
Twice as many defects faced my in compile as I'd expected, both on cycle 1 and cycle 2. My review procedures are not doing well.
Test
Test took almost twice as long as predicted, thanks to a couple of sneaky little problems which could have been caught sooner (such as by using defined methods in my design review!). Finally, however, I got reasonable output:
Table 11-3. D17: Test Results Format -- Program 10A
| Test | Parameter | Expected Value | Actual Value - C++ | Actual Value - Eiffel |
| Table D16 | ||||
| Beta0 | 0.56645 | 0.566457 | 0.566457 | |
| Beta1 | 0.06533 | 0.065329 | 0.065329 | |
| Beta2 | 0.008719 | 0.008719 | 0.008719 | |
| Beta3 | 0.15105 | 0.151049 | 0.151049 | |
| Projected Hours | 20.76 | 20.7574 | 20.757369 | |
| UPI(70%) | 26.89 | 26.8888 | 26.888841 | |
| LPI(70%) | 14.63 | 14.6259 | 14.625897 | |
| UPI(90%) | 33.67 | 33.6731 | 33.673056 | |
| LPI(90%) | 7.84 | 7.84168 | 7.841682 | |
| Appendix A | ||||
| Beta0 | 6.7013 | 6.701337 | 6.701337 | |
| Beta1 | 0.0784 | 0.078366 | 0.078336 | |
| Beta2 | 0.0150 | 0.015041 | 0.015041 | |
| Beta3 | 0.2461 | 0.246056 | 0.246056 | |
| Projected Hours | 140.9 | 140.902 | 140.901986 | |
| UPI(70%) | 179.7 | 179.752 | 179.751770 | |
| LPI(70%) | 102.1 | 102.052 | 102.052202 | |
| UPI(90%) | 222.74 | 222.737 | 222.737419 | |
| LPI(90%) | 59.06 | 59.0666 | 59.066552 |
Postmortem
PSP3 Project Plan Summary
Table 11-4. Project Plan Summary
| Student: | Victor B. Putz | Date: | 000206 |
| Program: | Multiple Regression | Program# | 10A |
| Instructor: | Wells | Language: | C++ |
| Summary | Plan | Actual | To date |
| Loc/Hour | 46 | 45.6 | 46 |
| Planned time | 285 | 1228 | |
| Actual time | 498 | 1746 | |
| CPI (cost/performance index) | 0.70 | ||
| %reused | 76 | 67 | 51 |
| Test Defects/KLOC | 30 | 24 | 29 |
| Total Defects/KLOC | 140 | 164 | 145 |
| Yield (defects before test/total defects) | 79 | 85 | 80 |
| % Appraisal COQ | 6 | 13.7 | 7 |
| % Failure COQ | 28 | 29.5 | 28.5 |
| COQ A/F Ratio | 0.21 | 0.46 | 0.25 |
| Program Size | Plan | Actual | To date |
| Base | 20 | 20 | |
| Deleted | 0 | 0 | |
| Modified | 1 | 1 | |
| Added | 238 | 378 | |
| Reused | 804 | 804 | 2502 |
| Total New and Changed | 239 | 379 | 2110 |
| Total LOC | 1062 | 1202 | 4874 |
| Upper Prediction Interval (70%) | 326 | ||
| Lower Prediction Interval (70%) | 152 |
| Time in Phase (min): | Plan | Actual | To Date | To Date% |
| Planning | 57 | 65 | 514 | 23 |
| High-Level Design | 0 | 38 | 38 | 1 |
| High-Level Design Review | 0 | 4 | 4 | < 1 |
| Detailed Design | 40 | 72 | 386 | 14 |
| Detailed Design Review | 6 | 56 | 109 | 4 |
| Code | 71 | 88 | 656 | 24 |
| Code Review | 9 | 12 | 85 | 3 |
| Compile | 17 | 51 | 183 | 7 |
| Test | 63 | 96 | 603 | 22 |
| Postmortem | 20 | 16 | 176 | 6 |
| Total | 285 | 498 | 2754 | 100 |
| Total Time UPI (70%) | 322 | |||
| Total Time LPI (70%) | 249 | |||
| Defects Injected | Actual | To Date | To Date % | |
| Plan | 0 | 0 | 0 | |
| High-Level Design | 0 | 0 | 0 | 0 |
| High-Level Design Review | 0 | 0 | 0 | 0 |
| Detailed Design | 11 | 20 | 97 | 32 |
| Design Review | 0 | 0 | 0 | 0 |
| Code | 22 | 40 | 200 | 66 |
| Code Review | 0 | 0 | 0 | 0 |
| Compile | 0 | 0 | 3 | < 1 |
| Test | 0 | 2 | 5 | 2 |
| Total development | 33 | 62 | 305 | 100 |
| Defects Removed | Actual | To Date | To Date % | |
| Planning | 0 | 0 | 0 | |
| High-Level Design | 0 | 0 | 0 | 0 |
| High-Level Design Review | 0 | 0 | 0 | 0 |
| Detailed Design | 0 | 0 | 0 | |
| Design Review | 2 | 8 | 23 | 8 |
| Code | 6 | 8 | 53 | 17 |
| Code Review | 3 | 6 | 29 | 10 |
| Compile | 15 | 31 | 138 | 45 |
| Test | 7 | 9 | 62 | 20 |
| Total development | 33 | 62 | 305 | 100 |
| After Development | 0 | 0 | 0 | |
| Defect Removal Efficiency | Plan | Actual | To Date | |
| Defects/Hour - Design Review | 22.5 | 8.5 | 12.66 | |
| Defects/Hour - Code Review | 24.2 | 30 | 20.5 | |
| Defects/Hour - Compile | 56.3 | 36.5 | 45.2 | |
| Defects/Hour - Test | 6.9 | 5.6 | 6.2 | |
| DRL (design review/test) | 3.26 | 1.54 | 2.04 | |
| DRL (code review/test) | 3.5 | 5.36 | 3.3 | |
| DRL (compile/test) | 8.16 | 6.52 | 7.3 |
| Eiffel code/compile/test |
| Time in Phase (min) | Actual | To Date | To Date % |
| Code | 65 | 434 | 48 |
| Code Review | 14 | 54 | 6 |
| Compile | 26 | 159 | 18 |
| Test | 56 | 248 | 28 |
| Total | 161 | 895 | 100 |
| Defects Injected | Actual | To Date | To Date % |
| Design | 6 | 12 | 7 |
| Code | 30 | 168 | 93 |
| Compile | 0 | 0 | 0 |
| Test | 0 | 1 | < 1 |
| Total | 36 | 181 | 100 |
| Defects Removed | Actual | To Date | To Date % |
| Code | 2 | 3 | 2 |
| Code Review | 4 | 20 | 11 |
| Compile | 21 | 109 | 60 |
| Test | 9 | 49 | 27 |
| Total | 36 | 181 | 100 |
| Defect Removal Efficiency | Actual | To Date | |
| Defects/Hour - Code Review | 17.14 | 22.2 | |
| Defects/Hour - Compile | 48.46 | 41.1 | |
| Defects/Hour - Test | 9.64 | 11.9 | |
| DRL (code review/test) | 1.8 | 1.9 | |
| DRL (compile/test) | 5.03 | 3.5 |
Time Recording Log
Table 11-5. Time Recording Log
| Student: | Date: | 000204 | |
| Program: |
| Start | Stop | Interruption Time | Delta time | Phase | Comments |
| 000204 07:43:21 | 000204 08:50:11 | 2 | 64 | plan | |
| 000205 09:12:21 | 000205 09:50:14 | 0 | 37 | high-level design | |
| 000205 09:51:42 | 000205 09:55:38 | 0 | 3 | high-level design review | #cycle 1 |
| 000206 09:42:35 | 000206 11:07:55 | 43 | 42 | design | |
| 000206 11:34:37 | 000206 12:21:08 | 0 | 46 | design review | |
| 000206 12:28:47 | 000206 14:20:53 | 57 | 55 | code | |
| 000206 14:20:54 | 000206 14:28:16 | 0 | 7 | code review | |
| 000206 14:28:48 | 000206 14:52:31 | 0 | 23 | compile | |
| 000206 14:52:34 | 000206 15:20:15 | 0 | 27 | test | #cycle 2 |
| 000206 15:25:24 | 000206 15:55:05 | 0 | 29 | design | |
| 000206 15:56:18 | 000206 16:10:47 | 5 | 9 | design review | |
| 000206 16:10:49 | 000206 16:51:55 | 7 | 34 | code | |
| 000206 16:52:00 | 000206 16:56:13 | 0 | 4 | code review | |
| 000206 16:59:43 | 000206 17:26:32 | 0 | 26 | compile | |
| 000206 17:26:39 | 000206 18:34:56 | 0 | 68 | test | |
| 000206 18:45:02 | 000206 19:00:35 | 0 | 15 | postmortem | |
Table 11-6. Time Recording Log
| Student: | Date: | 000207 | |
| Program: |
| Start | Stop | Interruption Time | Delta time | Phase | Comments |
| 000207 18:43:01 | 000207 19:20:52 | 2 | 35 | code | |
| 000207 19:27:21 | 000207 19:34:54 | 0 | 7 | code review | |
| 000207 19:35:03 | 000207 19:43:04 | 0 | 8 | compile | |
| 000207 19:43:47 | 000207 20:03:43 | 0 | 19 | test | #cycle 2 |
| 000207 20:05:57 | 000207 20:35:38 | 0 | 29 | code | |
| 000207 20:36:21 | 000207 20:42:24 | 0 | 6 | code review | |
| 000207 20:42:27 | 000207 21:01:18 | 0 | 18 | compile | |
| 000207 21:02:31 | 000207 21:38:25 | 0 | 35 | test | |
Defect Recording Log
Table 11-7. Defect Recording Log
| Student: | Date: | 000204 | |
| Program: |
| Defect found | Type | Reason | Phase Injected | Phase Removed | Fix time | Comments |
| 000206 11:37:47 | wa | ig | design | design review | 5 | changed reduction_coefficients algorithm to properly produce a row of reduced coefficients |
| 000206 11:48:13 | wn | ig | design | design review | 1 | was using obsolete mult_and_sum_array instead of mult_array and sum_array |
| 000206 11:50:27 | wn | ig | design | design review | 1 | again, using obsolete mult_and_sum_array |
| 000206 11:53:00 | md | ig | design | design review | 1 | added implementation for mult_array_by_scalar and add_arrays |
| 000206 11:56:45 | ma | cm | design | design review | 0 | forgot to increment loop counter |
| 000206 11:58:27 | wa | ig | design | design review | 22 | factored array tail/head/sum etc logic into numeric_array class, changed base of number_array_list to reflect |
| 000206 12:30:33 | wt | ig | design | code | 2 | had designated sum's return type as numeric_array instead of like item |
| 000206 12:41:56 | ct | om | design | code | 1 | forgot some ensure contracts |
| 000206 12:54:21 | wt | om | design | code | 1 | minor-- declared no return type for first_solution_coefficient |
| 000206 12:58:33 | ct | om | design | code | 3 | improved contracts on add_coefficients |
| 000206 13:02:48 | ma | ig | design | code | 1 | missed inclusion of reduced_solver.solution in solution |
| 000206 13:16:47 | wa | ig | design | code | 1 | missed correct extraction of first_row_arguments from coefficients |
| 000206 14:24:42 | sy | ty | code | code review | 0 | forgot parentheses on no-arg feature |
| 000206 14:25:15 | sy | ty | code | code review | 0 | forgot parentheses on no-arg feature |
| 000206 14:25:41 | sy | om | code | code review | 0 | forgot const on features |
| 000206 14:27:04 | wn | cm | code | code review | 0 | was using coefficients.size rather than first_row.size |
| 000206 14:31:45 | wn | om | code | compile | 0 | forgot to rename number_array_list to number_array_list_3, etc. |
| 000206 14:32:20 | sy | om | code | compile | 0 | forgot to #include gaussian_solver.h |
| 000206 14:33:22 | wn | cm | code | compile | 0 | gaussian_solver uses add_coefficients, not add_entry... |
| 000206 14:34:20 | wn | cm | code | compile | 0 | didn't change std::vector< double > to numeric_array |
| 000206 14:39:18 | sy | cm | code | compile | 0 | forgot to put in a missing variable name |
| 000206 14:40:06 | sy | ty | code | compile | 0 | used = instead of == for comparison |
| 000206 14:40:25 | sy | ty | code | compile | 0 | mistakenly put "." instead of "_" in variable name |
| 000206 14:41:22 | ma | cm | code | compile | 0 | forgot to return Result |
| 000206 14:41:35 | sy | cm | code | compile | 0 | forgot parentheses on no-arg feature |
| 000206 14:43:37 | wn | cm | code | compile | 0 | used tail() instead of end() for last iterator in array |
| 000206 14:44:22 | sy | cm | code | compile | 0 | forgot parentheses on no-arg feature |
| 000206 14:44:44 | sy | cm | code | compile | 0 | forgot to #include stdio |
| 000206 14:45:34 | sy | ty | code | compile | 0 | didn't separate class and feature with scope operator |
| 000206 14:50:42 | iu | ig | code | compile | 1 | lists in C++ use different interface (not scalar-index) |
| 000206 14:53:33 | wn | cm | code | test | 7 | for fully-reduced solution, was calculating the inverse of the correct answer |
| 000206 15:02:10 | wt | cm | code | test | 17 | OH, COME ON! I accidentally declared the Result type as bool, and the compiler never warned me, so the Result was always 1... |
| 000206 16:00:20 | wc | ig | code | design review | 0 | wrong loop termination (i+1, not i) |
| 000206 16:02:04 | mc | ig | code | design review | 0 | missed sqrt on subtotal for prediction_range |
| 000206 16:18:34 | ct | ig | design | code | 0 | missed ensure contract in gaussian_solver_term |
| 000206 16:27:29 | ct | ig | design | code | 0 | didn't have ensure contract in variance_series |
| 000206 16:53:58 | sy | ty | code | code review | 0 | misplaced parentheses |
| 000206 16:54:55 | ma | cm | code | code review | 0 | didn't return Result |
| 000206 17:00:14 | wt | cm | code | compile | 0 | full_variance_series was returning incorrect type (number_array_list instead of number_array_list_3) |
| 000206 17:06:40 | sy | ig | code | compile | 3 | grrr... C++ can't handle recursive class definitions, so had to break off a separate gaussian_solver_implementation |
| 000206 17:11:54 | sy | cm | code | compile | 0 | parentheses on no-arg feature |
| 000206 17:12:11 | sy | cm | code | compile | 0 | parentheses on no-arg feature |
| 000206 17:12:58 | mc | cm | code | compile | 0 | forgot to sum a series |
| 000206 17:13:28 | sy | cm | code | compile | 0 | parentheses on no-arg feature |
| 000206 17:13:55 | sy | ty | code | compile | 0 | mistyped variable name |
| 000206 17:14:15 | sy | ty | code | compile | 0 | := instead of = for assignment |
| 000206 17:14:59 | wn | cm | code | compile | 0 | wrong name for a feature-- mean_by_series instead of by field! |
| 000206 17:15:52 | iu | cm | code | compile | 0 | forgot to pass field index to mapped_to! |
| 000206 17:17:18 | wa | cm | code | compile | 0 | was selecting a series when I shouldn't have been |
| 000206 17:17:52 | sy | cm | code | compile | 0 | parentheses, no-arg feature |
| 000206 17:18:49 | wa | cm | code | compile | 0 | tried sum instead of sum_by_field |
| 000206 17:19:40 | sy | cm | code | compile | 0 | parentheses, no-arg feature |
| 000206 17:20:14 | sy | cm | code | compile | 0 | parentheses, no-arg feature |
| 000206 17:22:56 | sy | om | code | compile | 0 | did not #include t_distribution.h |
| 000206 17:25:12 | sy | om | test | compile | 0 | extracting the implementation details from gaussian_solver means I have to write TWO access functions (const/non-const) for coefficients. Lucky me. |
| 000206 17:28:57 | iu | om | design | test | 5 | multiplied_by_list requires field counts to be the same, so you must select the series first. I bet I'll see this again. |
| 000206 17:36:00 | wa | ig | design | test | 5 | multiplied_by_list was broken; wasn't using rhs.tail |
| 000206 17:42:13 | md | ig | test | test | 17 | Ah, yes... when we converted gaussian_solver to a dynamic implementation, we forgot to make a copy constructor. Hijinks ensued |
| 000206 18:01:12 | ct | ig | design | test | 0 | bad contract on gauss_solution == field_count - 1; should be == field_count |
| 000206 18:02:00 | ct | ig | design | test | 1 | ...same contract; entry_count > 0 should imply the previous contract |
| 000206 18:05:07 | wc | om | design | test | 16 | variance was using entry_count - 4 instead of entry_count - field_count |
| 000206 18:22:21 | wa | cm | design | test | 7 | DANG! Missed obvious incorrect assignment in prediction_range( the numerator calculation ) |
Table 11-8. Defect Recording Log
| Student: | Date: | 000207 | |
| Program: |
| Defect found | Type | Reason | Phase Injected | Phase Removed | Fix time | Comments |
| 000207 19:01:00 | ct | ig | design | code | 0 | contract in add_coefficients needed work |
| 000207 19:29:27 | wn | ty | code | code review | 0 | used count instead of sum in calculation |
| 000207 19:29:55 | mi | om | code | code review | 2 | forgot to implement make_empty |
| 000207 19:35:37 | sy | cm | code | compile | 0 | forgot "then" after "if" |
| 000207 19:36:01 | sy | cm | code | compile | 0 | forgot colon between feature and its return value |
| 000207 19:37:15 | wt | cm | code | compile | 1 | forgot-- had to update number_array_list_3 to use numeric_array |
| 000207 19:39:03 | wn | cm | code | compile | 0 | mistyped item as Item |
| 000207 19:41:46 | sy | ig | code | compile | 0 | can't list a non-exported feature in the require clause of an exported feature |
| 000207 19:42:24 | wn | cm | code | compile | 0 | mistyped possible_solution as test_solution |
| 000207 19:44:06 | wc | ig | code | test | 1 | testing for equality with doubles is dangerous... used in_range and it got better. |
| 000207 19:45:52 | mc | cm | code | test | 3 | forgot that manifest strings in Eiffel are not constant! |
| 000207 19:49:54 | ex | ig | code | test | 11 | bad test data |
| 000207 20:01:47 | wc | cm | design | test | 1 | is_valid_solution was using count + 1 instead of count - 1 for valid number of terms in possible solution |
| 000207 20:19:57 | wa | ig | design | code | 1 | same as in the C++ version-- bad alg in design for gaussian_solver_term |
| 000207 20:37:21 | ma | cm | code | code review | 0 | forgot to increment loop counter |
| 000207 20:41:09 | wa | cm | design | code review | 0 | wrong algorithm in prediction_range (same as C++ error) |
| 000207 20:42:36 | sy | cm | code | compile | 0 | = instead of :=... |
| 000207 20:43:22 | sy | cm | design | compile | 0 | poorly mismatched parentheses |
| 000207 20:44:14 | sy | cm | code | compile | 0 | separated different-type parameters by , instead of ; |
| 000207 20:45:08 | wn | cm | code | compile | 0 | wrong name for variance; should have been full_variance, etc. |
| 000207 20:46:26 | sy | ig | code | compile | 4 | forgot-- you don't separate "else if" |
| 000207 20:51:48 | wn | ty | code | compile | 0 | mistyped a name |
| 000207 20:52:18 | wn | cm | code | compile | 0 | silly person! mistyped function name |
| 000207 20:53:10 | wn | cm | code | compile | 1 | renamed "prediction_values" to "parameters" |
| 000207 20:54:34 | wn | cm | code | compile | 0 | typed "sum_by_series" instead of "sum_by_field" |
| 000207 20:55:15 | wc | ig | code | compile | 0 | er... can't use "0 < x < 4", must be "0 < x and x < 4" etc |
| 000207 20:55:56 | wn | cm | code | compile | 0 | had to change the variance, standard_deviation, etc calls to full_variance, etc. |
| 000207 20:56:58 | mc | cm | code | compile | 0 | had to separate make_from_entry and suffixed_by_list |
| 000207 20:58:16 | mc | cm | code | compile | 0 | didn't initialize t correctly |
| 000207 20:59:40 | iu | cm | code | compile | 0 | wasn't declaring a field to use in mapped_to |
| 000207 21:00:06 | mc | cm | code | compile | 0 | wasn't doing appropriate to_string calls to print doubles |
| 000207 21:02:34 | ma | cm | code | test | 5 | er... durn thang; eiffel arrays start at index 1, not 0. This will probably cause me pain. |
| 000207 21:11:43 | wa | ig | code | test | 0 | was not allowing zero entries for full_variation_series, disrupting recursion |
| 000207 21:14:58 | wa | cm | design | test | 0 | was calculating predictions wrong! |
| 000207 21:16:28 | ma | cm | code | test | 0 | missed initialization of square! |
| 000207 21:18:11 | wa | cm | code | test | 19 | used / instead of - for a calculation. Stupid, stupid... (and this was the most time-consuming) |