Program 9a: Normal Distribution fit
Using a linked list, write a program to do a chi-squared test for a normal distribution.
Given Requirements
Requirements: Write program 9a to calculate the degree to which a string of n real numbers is normally distributed. The methods and formulas used in this calculation are explained on page 529 [of the text]. Use program 5a to calculate the values of the normal and chi-squared distributions. Assume than n is > 20 and an even multiple of 5. Use program 8a to sort the numbers in ascending order. Testing: Thoroughly test the program. As one test, use the LOC/Method data in table D14 as a test case [note: this is the same data from program 8a]. Here, the result should be Q=34.4 with a probability value < 0.005 that the data are normally distributed. The solution to this case is shown [in the text]. Submit a test report that includes the test results and uses the format in table D15 Table 10-1. D15: Test Results Format -- program 9a
| ||||||||||||||
| --[Humphrey95] | ||||||||||||||
Planning
Requirements
I'll make heavy reuse of the parsing and number array list classes used in program 8a, which means that the data input format will remain the same (note-- in program 8a, I suggested that the first usable line of the input file be a single number, the number of fields in the file; since the number of fields can be extrapolated from the first historical data entry, this requirement has been removed).
So much for getting the numbers into the program. Where we run into a problem is the next bit-- which series are we going to check for normality? If this is going to be reused, how shall we decide which series to use?
The simple response would be to simply check all the series, but I'll do something slightly different-- after the historical data terminator, I'll make the input consist of commands and numbers; in other words, something like this:
... 58, 19.33 305, 25.42 stop -- end of data normality-check-on-series 1 -- request a normality check on the first series |
This will allow us to add further commands in the future, paving the way for some minor expandibility (considering that there is only one more program in this series, that may be unnecessary).
When the normality-check-on-series command is encountered, the program will perform a normality check on the given series (series 1 being the first set of numbers, and so on), printing the Q and 1-p results, thusly:
Normality check on series: 1 Q: 34.4 (1-p): 7.6e-5 |
Size Estimate
To do the size estimate-- and to make it worthwhile-- I'm going to do a bit more of a conceptual design than I have earlier, listing my appropriate classes and the methods I think I'll need. The algorithm in use in program 9a is considerably more complex than those used in other programs (or at least it seems to me), so I need to do more preparation here.
A quick conceptual design using Dia gives us the following:
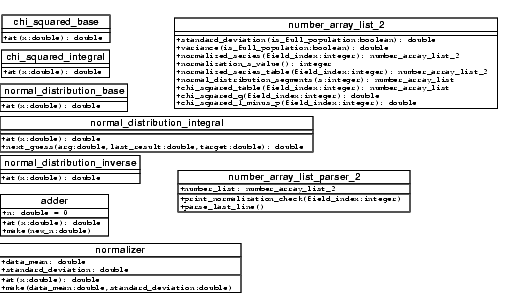
Note the heavy use of single_variable_function subclasses (it's not depicted well, but each class in the preliminary design except for number_array_list_2 and number_array_list_parser_2 is a subclass of single_variable_function. The normal_distribution_inverse class will be used to calculate the values of the normal distribution for S segments. The tex lists these for certain values of S (table A24 in [Humphrey95]), and we can use the table (since the requirements guarantee the numbers will be divisible by 5) but this will be more general.
With that in mind, our size estimating template gives us a PROBE-generated estimate of 239 new/changed LOC.
Resource/Time Estimate
Historical data gives us a PROBE-generated estimate of 285 minutes for this project.
Development
Design
Once again, I'm using a cluster of tiny single_variable_function classes to do much of the work. I also reconstruct the "by-hand" tables as per the algorithm in [Humphrey95]-- not because they are necessary for the computation, but because they will simplify testing by showing results similar to those in the text. Our preliminary design is fleshed out as follows:
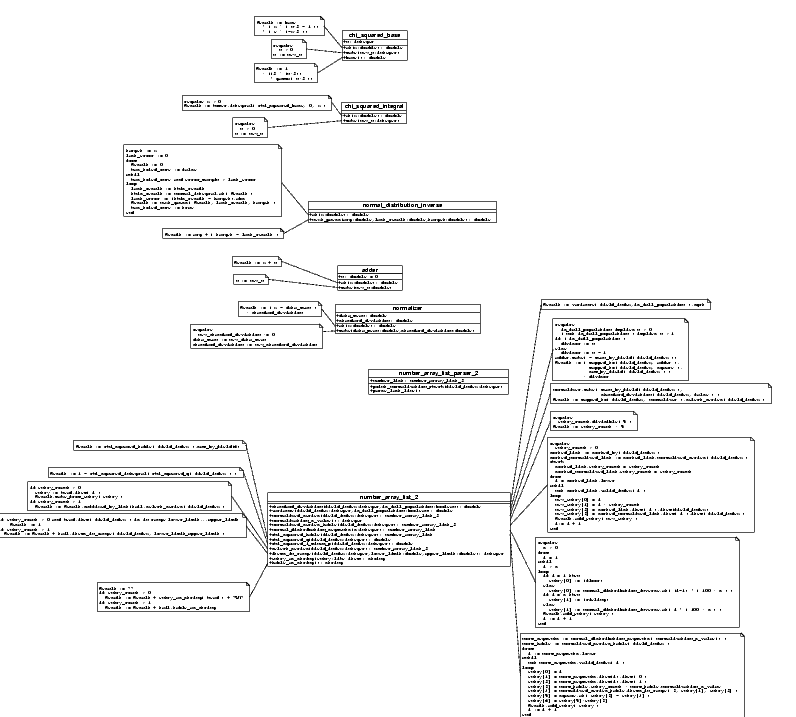
Design Review
Actually, not all that many defects were caught by the design review this time around, and few of those were show-stoppers. The basic design seems reasonable.
Code
Reused Code
The error_log, gamma_function, is_double_equal, normal_function_base, simple_input_parser, simpson_integrator, square, and whitespace_stripper modules were used in their entirety. Much code from number_array_list and number_array_list_parser was reused, but those classes are reprinted here since much was changed in number_array_list.
Part of the design had to be changed because I had originally planned to inherit from number_array_list to create number_array_list_2-- unfortunately, many of the functions returned by number_array_list did not (of course) return values of number_array_list_2-- meaning that I couldn't chain together functions as easily as I wanted to, which was unacceptable; as a result, I just expanded the original class. I did not have a chance to verify if "like current" in Eiffel would fix these problems (it may well have done so!)
adder
#ifndef ADDER_H
#define ADDER_H
#ifndef SINGLE_VARIABLE_FUNCTION_H
#include "single_variable_function.h"
#endif
class adder : public single_variable_function
{
protected:
double addend;
public:
adder( double new_addend );
virtual double at( double x ) const;
};
#endif |
#include "adder.h"
adder::adder( double new_addend ) :
addend( new_addend )
{
}
double
adder::at( double x ) const
{
return x + addend;
}
|
chi_squared_base
/*
*/
#ifndef CHI_SQUARED_BASE_H
#define CHI_SQUARED_BASE_H
#ifndef SINGLE_VARIABLE_FUNCTION_H
#include "single_variable_function.h"
#endif
class chi_squared_base : public single_variable_function
{
protected:
int n;
public:
virtual double at( double x ) const;
double base( void ) const;
chi_squared_base( int new_n );
};
#endif
/*
*/ |
/*
*/
#include "chi_squared_base.h"
#ifndef GAMMA_FUNCTION_H
#include "gamma_function.h"
#endif
#include <math.h>
#include <iostream>
double
chi_squared_base::at( double x ) const
{
const double Result = base()
* pow( x, ( static_cast<double>(n) / 2.0 - 1.0 ) )
* exp( -x / 2.0 );
// if ( x == 0 || x == 10 )
// {
// gamma_function gamma;
// cout << "Chibase at " << x << "\n"
// << "n: " << n << "\n"
// << "2^(n/2) " << pow(2.0,static_cast<double>(n)/2.0) << "\n"
// << "gamma(n/2)" << gamma.at( static_cast<double>(n)/2.0 ) << "\n"
// << "Base: " << base() << "\n"
// << "x^(n/2 - 1): " << pow( x, ( static_cast< double >(n) / 2.0 - 1.0 ) ) << "\n"
// << "e^(-x/2) :" << exp( -x / 2.0 ) << "\n";
// }
return Result;
}
chi_squared_base::chi_squared_base( int new_n ) :
n ( new_n )
{
}
double
chi_squared_base::base( void ) const
{
gamma_function gamma;
const double Result = 1 / ( pow( 2.0, static_cast<double>(n)/2.0 ) * gamma.at( static_cast<double>(n)/2.0 ) );
return Result;
}
/*
*/ |
chi_squared_integral
#ifndef CHI_SQUARED_INTEGRAL_H
#define CHI_SQUARED_INTEGRAL_H
#ifndef SINGLE_VARIABLE_FUNCTION_H
#include "single_variable_function.h"
#endif
class chi_squared_integral : public single_variable_function
{
protected:
int n;
public:
virtual double at( double x ) const;
chi_squared_integral( int new_n );
};
#endif |
/*
*/
#include "chi_squared_integral.h"
#ifndef CHI_SQUARED_BASE_H
#include "chi_squared_base.h"
#endif
#ifndef CONTRACT_H
#include "contract.h"
#endif
#ifndef SIMPSON_INTEGRATOR_H
#include "simpson_integrator.h"
#endif
#include <math.h>
double
chi_squared_integral::at( double x ) const
{
REQUIRE( x >= 0 );
simpson_integrator homer;
chi_squared_base chi_base( n );
double Result = homer.integral( chi_base, 0, x );
return Result;
}
chi_squared_integral::chi_squared_integral( int new_n ) :
n( new_n )
{
REQUIRE( new_n > 0 );
}
/*
*/ |
normal_distribution_inverse
#ifndef NORMAL_DISTRIBUTION_INVERSE_H
#define NORMAL_DISTRIBUTION_INVERSE_H
#ifndef SINGLE_VARIABLE_FUNCTION_H
#include "single_variable_function.h"
#endif
class normal_distribution_inverse : public single_variable_function
{
public:
virtual double at( double x ) const;
double next_guess( double arg, double last_result, double target ) const;
};
#endif |
/*
*/
#include "normal_distribution_inverse.h"
#ifndef NORMAL_DISTRIBUTION_INTEGRAL_H
#include "normal_distribution_integral.h"
#endif
#include <math.h>
double
normal_distribution_inverse::at( double x ) const
{
const double target = x;
const double error_margin = 0.0000001;
double last_error = 0;
double Result = 0;
double this_result = 0;
bool has_tried_once = false;
normal_distribution_integral norm;
while ( !has_tried_once || ( last_error > error_margin ) )
{
const double last_result = this_result;
this_result = norm.at( Result );
last_error = fabs( this_result - target );
if ( last_error > error_margin )
{
Result = next_guess( Result, last_result, target );
}
has_tried_once = true;
}
return Result;
}
double
normal_distribution_inverse::next_guess( double arg, double last_result, double target ) const
{
double Result = arg + ( target - last_result );
return Result;
}
/*
*/ |
normalizer
#ifndef NORMALIZER_H
#define NORMALIZER_H
#ifndef SINGLE_VARIABLE_FUNCTION_H
#include "single_variable_function.h"
#endif
class normalizer : public single_variable_function
{
protected:
double data_mean;
double standard_deviation;
public:
normalizer( double new_data_mean, double new_standard_deviation );
virtual double at( double x ) const;
};
#endif |
#include "normalizer.h"
normalizer::normalizer( double new_data_mean, double new_standard_deviation ) :
data_mean( new_data_mean ),
standard_deviation( new_standard_deviation )
{
}
double
normalizer::at( double x ) const
{
return ( x - data_mean ) / standard_deviation;
}
|
number_array_list
/*
*/
#ifndef NUMBER_ARRAY_LIST_H
#define NUMBER_ARRAY_LIST_H
#include <list>
#include <vector>
#include <string>
#ifndef SINGLE_VARIABLE_FUNCTION_H
#include "single_variable_function.h"
#endif
class number_array_list : public std::list< std::vector< double > >
{
protected:
int m_field_count;
public:
int field_count( void ) const;
std::vector< double > head( void ) const;
number_array_list tail( void ) const;
number_array_list suffixed_by_item( const std::vector< double >& entry ) const;
number_array_list suffixed_by_list( const number_array_list& rhs ) const;
number_array_list mapped_to( int field_index, const single_variable_function& f ) const;
number_array_list multiplied_by_list( int field_index, const number_array_list& rhs ) const;
number_array_list sorted_by( int field_index ) const;
number_array_list items_less_than( int field_index, double value ) const;
number_array_list items_greater_than_or_equal_to( int field_index, double value ) const;
bool is_valid_entry( const std::vector< double >& entry ) const;
bool is_valid_field_index( int field_index ) const;
bool is_sorted_by( int field_index ) const;
double sum_by_field( int field_index ) const;
double mean_by_field( int field_index ) const;
int entry_count( void ) const;
void set_field_count( int new_field_count );
void add_entry( const std::vector< double >& entry );
void make_from_entry( const std::vector< double >& entry );
void make( void );
void make_from_list( const number_array_list& rhs );
number_array_list( void );
double standard_deviation( int field_index, bool is_full_population ) const;
double variance( int field_index, bool is_full_population ) const;
number_array_list normalized_series( int field_index ) const;
int normalization_s_value( void ) const;
number_array_list normalized_series_table( int field_index ) const;
number_array_list normal_distribution_segments( int s ) const;
number_array_list chi_squared_table( int field_index ) const;
double chi_squared_q( int field_index ) const;
double chi_squared_1_minus_p( int field_index ) const;
number_array_list select_series( int field_index ) const;
int items_in_range( int field_index, double lower_limit, double upper_limit ) const;
std::string entry_as_string( const std::vector< double >& entry ) const;
std::string table_as_string( void ) const;
};
#endif
/*
*/ |
/*
*/
#include "number_array_list.h"
#ifndef CONTRACT_H
#include "contract.h"
#endif
#ifndef ADDER_H
#include "adder.h"
#endif
#ifndef SQUARE_H
#include "square.h"
#endif
#ifndef NORMAL_DISTRIBUTION_INVERSE_H
#include "normal_distribution_inverse.h"
#endif
#ifndef CHI_SQUARED_INTEGRAL_H
#include "chi_squared_integral.h"
#endif
#ifndef NORMALIZER_H
#include "normalizer.h"
#endif
#include <math.h>
#include <stdio.h>
int
number_array_list::field_count( void ) const
{
return m_field_count;
}
std::vector< double >
number_array_list::head( void ) const
{
REQUIRE( entry_count() >= 1 );
return *(begin());
}
number_array_list
number_array_list::tail( void ) const
{
number_array_list Result;
if ( entry_count() > 1 )
{
number_array_list::const_iterator tail_head = begin();
++tail_head;
Result.insert( Result.begin(), tail_head, end() );
Result.m_field_count = field_count();
ENSURE( Result.entry_count() == entry_count() - 1 );
}
return Result;
}
number_array_list
number_array_list::suffixed_by_item( const std::vector< double >& entry ) const
{
number_array_list Result;
Result.make_from_list( *this );
Result.add_entry( entry );
ENSURE( Result.entry_count() == entry_count() + 1 );
return Result;
}
number_array_list
number_array_list::suffixed_by_list( const number_array_list& rhs ) const
{
number_array_list Result;
Result.make_from_list( *this );
for ( number_array_list::const_iterator iter = rhs.begin(); iter != rhs.end(); ++iter )
{
Result.add_entry( *iter );
}
ENSURE( Result.entry_count() == entry_count() + rhs.entry_count() );
return Result;
}
number_array_list
number_array_list::mapped_to( int field_index, const single_variable_function& f ) const
{
REQUIRE( is_valid_field_index( field_index ) );
number_array_list Result;
if ( entry_count() > 0 )
{
std::vector<double> new_entry = head();
new_entry[ field_index ] = f.at( head()[ field_index ] );
Result.make_from_list( Result.suffixed_by_item( new_entry ).suffixed_by_list( tail().mapped_to( field_index, f )));
}
ENSURE( Result.entry_count() == entry_count() );
return Result;
}
number_array_list
number_array_list::multiplied_by_list( int field_index, const number_array_list& rhs ) const
{
REQUIRE( entry_count() == rhs.entry_count() );
REQUIRE( field_count() == rhs.field_count() );
REQUIRE( is_valid_field_index( field_index ) );
number_array_list Result;
if ( entry_count() > 0 )
{
std::vector< double > new_entry = head();
new_entry[ field_index ] = head()[ field_index ] * rhs.head()[field_index];
Result.make_from_list( Result.suffixed_by_item( new_entry ).
suffixed_by_list( tail().multiplied_by_list( field_index, rhs ) ) );
}
ENSURE( Result.entry_count() == entry_count() );
return Result;
}
number_array_list
number_array_list::sorted_by( int field_index ) const
{
REQUIRE( is_valid_field_index( field_index ) );
number_array_list Result;
if ( is_sorted_by( field_index ) )
{
Result.make_from_list( *this );
}
else
{
Result.make_from_list( tail().items_less_than( field_index, head()[field_index] ).sorted_by( field_index ).
suffixed_by_item( head() ).
suffixed_by_list( tail().items_greater_than_or_equal_to( field_index, head()[field_index] ).sorted_by( field_index )));
}
ENSURE( Result.entry_count() == entry_count() );
return Result;
}
number_array_list
number_array_list::items_less_than( int field_index, double value ) const
{
REQUIRE( is_valid_field_index( field_index ) );
number_array_list Result;
for ( number_array_list::const_iterator iter = begin(); iter != end(); ++iter )
{
if ( (*iter)[field_index] < value )
{
Result.add_entry( *iter );
}
}
ENSURE( Result.entry_count() <= entry_count() );
return Result;
}
number_array_list
number_array_list::items_greater_than_or_equal_to( int field_index, double value ) const
{
REQUIRE( is_valid_field_index( field_index ) );
number_array_list Result;
for ( number_array_list::const_iterator iter = begin(); iter != end(); ++iter )
{
if ( (*iter)[field_index] >= value )
{
Result.add_entry(*iter);
}
}
ENSURE( Result.entry_count() <= entry_count() );
return Result;
}
bool
number_array_list::is_valid_entry( const std::vector<double>& entry ) const
{
bool Result = false;
if ( ( entry_count() == 0 )
|| ( ( entry_count() > 0 ) && ( entry.size() == field_count() ) ) )
{
Result = true;
}
return Result;
}
bool
number_array_list::is_valid_field_index( int field_index ) const
{
bool Result = true;
if ( entry_count() > 0 )
{
Result = ( 0 <= field_index ) && ( field_index < m_field_count );
}
return Result;
}
bool
number_array_list::is_sorted_by( int field_index ) const
{
REQUIRE( is_valid_field_index( field_index ) );
bool Result = true;
if ( entry_count() > 1 )
{
Result = ( head()[field_index] < tail().head()[field_index] ) && tail().is_sorted_by( field_index );
}
return Result;
}
double
number_array_list::sum_by_field( int field_index ) const
{
REQUIRE( is_valid_field_index( field_index ) )
double Result = 0;
if ( entry_count() > 0 )
{
Result = head()[field_index] + tail().sum_by_field( field_index );
}
return Result;
}
double
number_array_list::mean_by_field( int field_index ) const
{
REQUIRE( is_valid_field_index( field_index ) );
REQUIRE( entry_count() > 0 );
double Result = sum_by_field( field_index ) / static_cast<double>( entry_count() );
return Result;
}
int
number_array_list::entry_count( void ) const
{
return size();
}
void
number_array_list::set_field_count( int new_field_count )
{
REQUIRE( entry_count() == 0 );
m_field_count = new_field_count;
ENSURE( field_count() == new_field_count );
}
void
number_array_list::add_entry( const std::vector< double >& entry )
{
if ( entry_count() == 0 )
{
set_field_count( entry.size() );
}
REQUIRE( is_valid_entry( entry ) );
const int old_entry_count = entry_count();
push_back( entry );
ENSURE( entry_count() == old_entry_count + 1 );
}
void
number_array_list::make_from_entry( const std::vector<double>& entry )
{
make();
add_entry( entry );
ENSURE( entry_count() == 1 );
ENSURE( head() == entry );
}
void
number_array_list::make( void )
{
clear();
m_field_count = -1;
ENSURE( m_field_count == -1 );
ENSURE( entry_count() == 0 );
}
void
number_array_list::make_from_list( const number_array_list& rhs )
{
make();
insert( begin(), rhs.begin(), rhs.end() );
m_field_count = rhs.field_count();
ENSURE( entry_count() == rhs.entry_count() );
}
number_array_list::number_array_list( void )
{
make();
}
double
number_array_list::standard_deviation( int field_index, bool is_full_population ) const
{
double Result = sqrt( variance( field_index, is_full_population ) );
return Result;
}
double
number_array_list::variance( int field_index, bool is_full_population ) const
{
adder an_adder( -mean_by_field( field_index ) );
square a_square;
if ( is_full_population )
{
CHECK( entry_count() > 0 );
}
else
{
CHECK( entry_count() > 1 );
}
const double divisor = static_cast< double >( is_full_population ? entry_count() : entry_count() - 1 );
const double Result = mapped_to( field_index, an_adder ).
mapped_to( field_index, a_square ).sum_by_field( field_index ) / divisor;
return Result;
}
number_array_list
number_array_list::normalized_series( int field_index ) const
{
//cout << "Standard dev: " << standard_deviation( field_index, false ) << "\n";
normalizer a_normalizer( mean_by_field( field_index ), standard_deviation( field_index, false ) );
number_array_list Result = mapped_to( field_index, a_normalizer ).select_series( field_index );
//cout << "**in normalized_series**\n" << mapped_to( field_index, a_normalizer ).table_as_string() << "\n";
ENSURE( Result.entry_count() == entry_count() );
//cout << "**normalized_series result**\n" << Result.table_as_string() << "\n";
return Result;
}
int
number_array_list::normalization_s_value( void ) const
{
REQUIRE( entry_count() % 5 == 0 );
int Result = entry_count() / 5;
return Result;
}
number_array_list
number_array_list::normalized_series_table( int field_index ) const
{
REQUIRE( entry_count() > 0 );
number_array_list sorted_list;
sorted_list.make_from_list( sorted_by( field_index ) );
number_array_list sorted_normalized_list = sorted_list.normalized_series( field_index );
//cout << "Sorted list: \n" << sorted_list.table_as_string() << "\n";
//cout << "sorted normalized_list: \n" << sorted_normalized_list.table_as_string() << "\n";
CHECK( sorted_list.entry_count() == entry_count() );
CHECK( sorted_normalized_list.entry_count() == entry_count() );
number_array_list::const_iterator sorted_list_iter;
number_array_list::const_iterator sorted_normalized_list_iter;
int i = 0;
number_array_list Result;
for( i = 0, sorted_list_iter = sorted_list.begin(), sorted_normalized_list_iter = sorted_normalized_list.begin();
sorted_list_iter != sorted_list.end() && sorted_normalized_list_iter != sorted_normalized_list.end();
)//++i, ++sorted_list_iter, ++sorted_normalized_list_iter )
{
std::vector<double>new_entry;
new_entry.push_back( static_cast<double>(i + 1) );
new_entry.push_back( static_cast<double>(i + 1) / static_cast<double>(entry_count()));
new_entry.push_back( (*sorted_list_iter)[ field_index ] );
new_entry.push_back( (*sorted_normalized_list_iter)[ 0 ] );
Result.add_entry( new_entry );
++i;
++sorted_list_iter;
++sorted_normalized_list_iter;
}
ENSURE( Result.entry_count() == entry_count() );
return Result;
}
number_array_list
number_array_list::normal_distribution_segments( int s ) const
{
REQUIRE( s > 0 );
const double norm_floor = -10000;
const double norm_ceiling = 10000;
normal_distribution_inverse norm_inverse;
number_array_list Result;
for ( int i = 1; i <= s; ++i )
{
std::vector< double > new_entry;
if ( i == 1 )
{
new_entry.push_back( norm_floor );
}
else
{
new_entry.push_back( norm_inverse.at( ( static_cast<double>(i - 1) )
* ( 1.0 / static_cast< double >( s ) )));
}
if ( i == s )
{
new_entry.push_back( norm_ceiling );
}
else
{
new_entry.push_back( norm_inverse.at( ( static_cast< double >( i ) )
* ( 1.0 / static_cast< double >( s ) )));
}
Result.add_entry( new_entry );
}
return Result;
}
number_array_list
number_array_list::chi_squared_table( int field_index ) const
{
number_array_list normal_segments = normal_distribution_segments( normalization_s_value() );
number_array_list norm_table = normalized_series_table( field_index );
number_array_list Result;
square a_square;
//cout << "norm table\n" << norm_table.table_as_string() << "\n\n";
int i = 0;
number_array_list::const_iterator iter;
for ( i = 0, iter = normal_segments.begin(); iter != normal_segments.end(); ++iter, ++i )
{
std::vector< double > new_entry;
new_entry.push_back( i );
new_entry.push_back( (*iter)[0] );
new_entry.push_back( (*iter)[1] );
new_entry.push_back( static_cast< double >(norm_table.entry_count()) / norm_table.normalization_s_value() );
new_entry.push_back( static_cast< double >(norm_table.items_in_range( 3, new_entry[1], new_entry[2] ) ) );
new_entry.push_back( a_square.at( new_entry[3] - new_entry[4] ) );
new_entry.push_back( new_entry[5] / new_entry[ 3 ] );
Result.add_entry( new_entry );
}
return Result;
}
double
number_array_list::chi_squared_q( int field_index ) const
{
//cout << chi_squared_table( field_index ).table_as_string();
double Result = chi_squared_table( field_index ).sum_by_field( 6 );
return Result;
}
#ifndef CHI_SQUARED_BASE_H
#include "chi_squared_base.h"
#endif
double
number_array_list::chi_squared_1_minus_p( int field_index ) const
{
chi_squared_integral chi( normalization_s_value() - 1 );
double Result = 1 - chi.at( chi_squared_q( field_index ) );
return Result;
}
number_array_list
number_array_list::select_series( int field_index ) const
{
number_array_list Result;
if ( entry_count() > 0 )
{
std::vector< double >new_entry;
new_entry.push_back( head()[field_index] );
Result.add_entry( new_entry );
}
if ( entry_count() > 1 )
{
Result.make_from_list( Result.suffixed_by_list( tail().select_series( field_index ) ));
}
ENSURE( Result.entry_count() == entry_count() );
ENSURE( Result.field_count() == 1 );
return Result;
}
int
number_array_list::items_in_range( int field_index, double lower_limit, double upper_limit ) const
{
int Result = 0;
if (( entry_count() > 0 )
&& ( head()[field_index] > lower_limit )
&& ( head()[field_index] <= upper_limit ) )
{
Result = 1;
}
if ( entry_count() > 1 )
{
Result = Result + tail().items_in_range( field_index, lower_limit, upper_limit );
}
return Result;
}
std::string double_as_string( double x )
{
char buffer[ 1000 ];
sprintf( buffer, "%f", x );
return std::string( buffer );
}
std::string
number_array_list::entry_as_string( const std::vector< double >& entry ) const
{
std::string Result = "( ";
for ( std::vector< double >::const_iterator iter = entry.begin(); iter != entry.end(); ++iter )
{
Result = Result + double_as_string( *iter );
if ( ( iter + 1 ) != entry.end() )
{
Result = Result + ", ";
}
}
Result = Result + " )";
return Result;
}
std::string
number_array_list::table_as_string( void ) const
{
std::string Result = "";
if ( entry_count() > 0 )
{
Result = Result + entry_as_string( head() ) + "\n";
}
if ( entry_count() > 1 )
{
Result = Result + tail().table_as_string();
}
return Result;
}
/*
*/ |
number_array_list_parser_2
#ifndef NUMBER_ARRAY_LIST_PARSER_H
#define NUMBER_ARRAY_LIST_PARSER_H
#ifndef SIMPLE_INPUT_PARSER_H
#include "simple_input_parser.h"
#endif
#ifndef NUMBER_ARRAY_LIST_H
#include "number_array_list.h"
#endif
class number_array_list_parser_2: public simple_input_parser
{
protected:
number_array_list number_list;
enum state_t { Parsing_historical_data, Parsing_commands };
state_t state;
public:
virtual std::string transformed_line (const std::string & line) const;
std::string string_stripped_of_comments (const std::string & str) const;
static bool is_double (const std::string & str);
static double double_from_string (const std::string & str);
static const std::string & historical_data_terminator;
static const std::string & inline_comment_begin;
bool last_line_is_blank (void);
virtual void parse_last_line (void);
void parse_last_line_as_historical_data (void);
void parse_last_line_as_end_of_historical_data (void);
void parse_last_line_as_command( void );
void print_normalization_check( int field_index );
void make( void );
number_array_list_parser_2( void );
bool last_line_is_valid_historical_data( void ) const;
static std::vector< std::string > split_string( const std::string& string_to_split, const std::string& separator );
static std::string string_before_separator( const std::string& string_to_split, const std::string& separator );
static std::string string_after_separator( const std::string& string_to_split, const std::string& separator );
static std::vector< double > numbers_from_string( const std::string& string_to_split );
};
#endif |
/*
*/
#include "number_array_list_parser_2.h"
#ifndef WHITESPACE_STRIPPER_H
#include "whitespace_stripper.h"
#endif
#ifndef ERROR_LOG_H
#include "error_log.h"
#endif
#ifndef CONTRACT_H
#include "contract.h"
#endif
void
number_array_list_parser_2::make (void)
{
simple_input_parser::reset ();
state = Parsing_historical_data;
number_list.make ();
}
std::string number_array_list_parser_2::transformed_line (const std::string & str) const
{
return whitespace_stripper::string_stripped_of_whitespace (string_stripped_of_comments (str));
}
std::string
number_array_list_parser_2::string_stripped_of_comments (const std::string & str) const
{
const std::string::size_type comment_index = str.find (inline_comment_begin);
return str.substr (0, comment_index);
}
bool
number_array_list_parser_2::is_double (const std::string & str)
{
bool
Result = true;
char *
conversion_end = NULL;
strtod (str.c_str (), &conversion_end);
if (conversion_end == str.data ())
{
Result = false;
}
return Result;
}
double
number_array_list_parser_2::double_from_string (const std::string & str)
{
REQUIRE (is_double (str));
return strtod (str.c_str (), NULL);
}
const
std::string & number_array_list_parser_2::historical_data_terminator = "stop";
const
std::string & number_array_list_parser_2::inline_comment_begin = "--";
bool number_array_list_parser_2::last_line_is_blank (void)
{
if (last_line ().length () == 0)
{
return true;
}
else
{
return false;
}
}
void
number_array_list_parser_2::parse_last_line (void)
{
if (last_line_is_blank ())
{
return;
}
if ( state == Parsing_historical_data )
{
if ( last_line () == historical_data_terminator)
{
parse_last_line_as_end_of_historical_data ();
}
else
{
parse_last_line_as_historical_data ();
}
}
else
{
parse_last_line_as_command();
}
}
void
number_array_list_parser_2::parse_last_line_as_historical_data (void)
{
if ( last_line_is_valid_historical_data() )
{
const std::vector< double >this_entry = numbers_from_string( last_line() );
number_list.add_entry( this_entry );
}
else
{
error_log errlog;
errlog.log_error( std::string( "Invalid data entry: " ) + last_line() );
}
}
void
number_array_list_parser_2::parse_last_line_as_end_of_historical_data (void)
{
REQUIRE (last_line () == historical_data_terminator);
cout << "Historical data read; "
<< number_list.entry_count() << " entries, "
<< number_list.field_count() << " fields.\n";
state = Parsing_commands;
}
number_array_list_parser_2::number_array_list_parser_2 (void)
{
make();
}
bool
number_array_list_parser_2::last_line_is_valid_historical_data( void ) const
{
const std::vector< std::string > substrings = split_string( last_line(), "," );
bool Result = true;
//make sure we have a valid field count for the number_array_list
if ( ( number_list.entry_count() > 0 ) && ( substrings.size() != number_list.field_count() ) )
{
Result = false;
}
//...and that each substring can be interpreted as a double
for ( int i = 0; i < substrings.size(); ++i )
{
if ( !is_double( substrings[ i ] ) )
{
Result = false;
}
}
return Result;
}
std::vector< std::string >
number_array_list_parser_2::split_string( const std::string& string_to_split, const std::string& separator )
{
std::vector< std::string > Result;
const std::string prefix = string_before_separator( string_to_split, separator );
const std::string remainder = string_after_separator( string_to_split, separator );
Result.push_back( prefix );
if ( remainder.size() > 0 )
{
const std::vector< std::string > split_remainder = split_string( remainder, separator );
Result.insert( Result.end(), split_remainder.begin(), split_remainder.end() );
}
return Result;
}
std::string
number_array_list_parser_2::string_before_separator( const std::string& string_to_split, const std::string& separator )
{
const std::string::size_type separator_position = string_to_split.find( separator );
std::string Result;
if ( separator_position == string_to_split.npos )
{
//not found; result is entire string
Result = string_to_split;
}
else
{
Result = string_to_split.substr( 0, separator_position );
}
return Result;
}
std::string
number_array_list_parser_2::string_after_separator( const std::string& string_to_split, const std::string& separator )
{
const std::string::size_type separator_position = string_to_split.find( separator );
std::string Result;
if ( separator_position == string_to_split.npos )
{
//not found; result is empty
Result = "";
}
else
{
Result = string_to_split.substr( separator_position + separator.size(), string_to_split.size() );
}
return Result;
}
std::vector< double >
number_array_list_parser_2::numbers_from_string( const std::string& string_to_split )
{
const std::vector< std::string > number_strings = split_string( string_to_split, "," );
std::vector< double > Result;
for ( std::vector< std::string >::const_iterator iter = number_strings.begin(); iter != number_strings.end(); ++iter )
{
CHECK( is_double( *iter ) );
const double new_value = double_from_string( *iter );
Result.push_back( new_value );
}
return Result;
}
void
number_array_list_parser_2::parse_last_line_as_command( void )
{
std::string command = string_before_separator( last_line(), " " );
std::vector< string > arguments = split_string( string_after_separator( last_line(), " " ), " " );
if ( command == "normality_check_on_series" )
{
print_normalization_check( static_cast< int >( double_from_string( arguments[0] ) ) );
}
else
{
cout << "unknown command: " << last_line() << "\n";
}
}
void
number_array_list_parser_2::print_normalization_check( int field_index )
{
cout << "Normalization check on series: " << field_index << "\n";
cout << "Q: " << number_list.chi_squared_q( field_index ) << "\n";
cout << "(1-p): " << number_list.chi_squared_1_minus_p( field_index ) << "\n";
}
/*
*/ |
main
main.cpp |
adder.e
class ADDER
inherit
SINGLE_VARIABLE_FUNCTION
redefine
at
creation
make
feature {NONE}
addend : DOUBLE
--number added to each argument in at
make( new_addend : DOUBLE ) is
--create with given addend
do
addend := new_addend
end
feature {ANY}
at( x : DOUBLE ) : DOUBLE is
--x + addend
do
Result := x + addend
end
end
|
chi_squared_base.e
class CHI_SQUARED_BASE
--base calculation for the chi-squared distribution
inherit
SINGLE_VARIABLE_FUNCTION
redefine
at;
creation
make
feature {ANY}
n : INTEGER
--sample size of the distribution
make( new_n : INTEGER ) is
--creation, setting the sample size
require
new_n > 0
do
n := new_n;
end
base : DOUBLE is
--base of the equation
local
gamma : GAMMA_FUNCTION
do
!!gamma
Result := 1 / ( ( 2 ^ n ).sqrt * gamma.at( n.to_double / 2.0 ) )
end
at( x : DOUBLE ) : DOUBLE is
--value of the function at x
do
Result := base * ( ( x ^ (n-2) ).sqrt ) * ( -x/2.0 ).exp
end
end
|
chi_squared_integral.e
class CHI_SQUARED_INTEGRAL
inherit
SINGLE_VARIABLE_FUNCTION
redefine
at;
creation
make
feature {ANY}
n : INTEGER
--size of the distribution, in samples
make( new_n : INTEGER ) is
--creation
require
new_n > 0
do
n := new_n
end
at( x : DOUBLE ) : DOUBLE is
--integral evaluated from zero to the given number
require
x > 0.0
local
homer : SIMPSON_INTEGRATOR
chi_base : CHI_SQUARED_BASE
do
!!homer.make
!!chi_base.make(n)
Result := homer.integral( chi_base, 0, x )
end
end
|
normal_distribution_inverse.e
class NORMAL_DISTRIBUTION_INVERSE
--inverse of the normal distribution, used to make segment tables
--for normalization fit
inherit
SINGLE_VARIABLE_FUNCTION
redefine
at;
feature { ANY }
at( x : DOUBLE ) : DOUBLE is
--inverse of the normal distribution
local
target : DOUBLE
last_error : DOUBLE
last_result : DOUBLE
this_result : DOUBLE
has_tried_once : BOOLEAN
normal : NORMAL_DISTRIBUTION_INTEGRAL
error_margin : DOUBLE
do
from
target := x;
last_error := 0;
last_result := 0;
this_result := 0;
Result := 0
has_tried_once := false
error_margin := 0.0000001
!!normal.make
until
has_tried_once and error_margin > last_error
loop
last_result := this_result
this_result := normal.at( Result );
last_error := (this_result - target).abs
if ( last_error > error_margin ) then
Result := next_guess( Result, last_result, target )
end
has_tried_once := true;
end
end
next_guess( arg, last_result, target : DOUBLE ) : DOUBLE is
--next guess in the iterative scheme of things
do
Result := arg + ( target - last_result )
end
end
|
normalizer.e
class NORMALIZER
inherit
SINGLE_VARIABLE_FUNCTION
redefine
at
creation
make
feature { NONE }
data_mean : DOUBLE
standard_deviation : DOUBLE
make( new_data_mean, new_standard_deviation : DOUBLE ) is
--create with given feature values
do
data_mean := new_data_mean
standard_deviation := new_standard_deviation
end
feature {ANY}
at( x : DOUBLE ) : DOUBLE is
--(x-mean)/standard_dev
do
Result := ( x - data_mean ) / standard_deviation
end
end
|
number_array_list.e
class NUMBER_ARRAY_LIST
inherit
LINKED_LIST[ ARRAY[ DOUBLE ] ]
redefine
make;
creation
make, make_from_entry, make_from_list
feature { ANY }
field_count : INTEGER
--number of fields allowed in an entry
head : like item is
--first item
require
entry_count >= 1
do
Result := first;
end
tail : like Current is
--all items after the first
do
!!Result.make
if ( entry_count > 1 ) then
Result := slice( lower + 1, upper );
Result.set_field_count( field_count )
end --if
ensure
( entry_count > 1 ) implies Result.entry_count = entry_count - 1 and Result.field_count = field_count
end
suffixed_by_list( rhs: like Current ) : like Current is
--the list, suffixed by another list
local
i : INTEGER
do
!!Result.make_from_list( Current );
from
i := rhs.lower
until
not rhs.valid_index ( i )
loop
Result.add_entry( rhs.item( i ) );
i := i + 1
end --from
ensure
Result.entry_count = entry_count + rhs.entry_count
end
make_from_entry( entry : like item ) is
--clear the list, then add the entry
do
make
add_entry( entry )
ensure
head.is_equal( entry )
field_count = entry.count
end
make is
--clear the list
do
Precursor
field_count := -1
ensure
entry_count = 0
field_count = -1
end
make_from_list( rhs: like Current ) is
--clear the list, setting it equal to another list
do
from_collection( rhs )
field_count := rhs.field_count
end
sum_by_field( field_index : INTEGER ) : DOUBLE is
--the sum of a given field over all entries
require
is_valid_field_index( field_index )
do
if entry_count = 0 then
Result := 0
else
Result := head.item( field_index ) + tail.sum_by_field( field_index )
end
end
mean_by_field( field_index : INTEGER ) : DOUBLE is
--the mean of a given field over all entries
require
is_valid_field_index( field_index )
entry_count >= 1
do
Result := sum_by_field( field_index ) / entry_count.to_double
end
entry_count : INTEGER is
--the number of entries
do
Result := count
end
add_entry( new_entry : like item ) is
-- adds an entry to the end of the list
require
is_valid_entry( new_entry )
do
if entry_count = 0 then
set_field_count( new_entry.count )
end
add_last( new_entry )
ensure
entry_count = old entry_count + 1
end
mapped_to( field_index : INTEGER; f: SINGLE_VARIABLE_FUNCTION ) : like Current is
--the elements, with the given field mapped to f
require
is_valid_field_index( field_index )
local
new_entry : like item
do
!!Result.make
if entry_count > 0 then
new_entry := head.twin
new_entry.put( f.at( head.item(field_index) ), field_index )
Result.add_entry( new_entry );
Result := Result.suffixed_by_list( tail.mapped_to( field_index, f ) )
end -- if
ensure
Result.entry_count = entry_count
end
multiplied_by_list( field_index : INTEGER; rhs : like Current ) : like Current is
--the elements, with the given field multiplied by the
--corresponding field in rhs
require
entry_count = rhs.entry_count
field_count = rhs.field_count
is_valid_field_index( field_index )
local
new_entry : like item
do
!!Result.make
if entry_count > 0 then
new_entry := head
new_entry.put( head.item( field_index ) * rhs.head.item( field_index ), field_index )
Result.add_entry( new_entry )
Result := Result.suffixed_by_list( tail.multiplied_by_list( rhs.tail ) )
end
ensure
Result.entry_count = entry_count
end
sorted_by( field_index : INTEGER ) : like Current is
--the list, sorted by the given field
require
is_valid_field_index( field_index )
do
if is_sorted_by( field_index ) then
!!Result.make_from_list( Current )
else
!!Result.make_from_list( tail.items_less_than( field_index, head.item( field_index ) ).sorted_by( field_index ).
suffixed_by_item( head ).
suffixed_by_list( tail.items_greater_than_or_equal_to( field_index, head.item( field_index ) ).sorted_by( field_index ) ) )
end -- if
ensure
Result.entry_count = entry_count
end
is_valid_entry( entry : like item ) : BOOLEAN is
--whether entry is a valid entry
do
if ( entry_count = 0 and entry.count > 0 ) or ( entry.count = field_count and entry.lower = 1 ) then
Result := true
else
Result := false
end
end
items_less_than( field_index : INTEGER; value : DOUBLE ) : like Current is
--list of items less than the given value in the given field
require
is_valid_field_index( field_index )
local
i : INTEGER
do
!!Result.make
from
i := lower
until
not valid_index( i )
loop
if not( item( i ).item( field_index ) >= value ) then
Result.add_entry( item( i ) )
end
i := i + 1
end
ensure
Result.entry_count <= entry_count
end
items_greater_than_or_equal_to( field_index : INTEGER; value : DOUBLE ) : like Current is
--list of items greater than or equal to the given value in the
--given field
require
is_valid_field_index( field_index )
local
i : INTEGER
do
!!Result.make
from
i := lower
until
not valid_index( i )
loop
if item(i).item( field_index ) >= value then
Result.add_entry( item( i ) )
end
i := i + 1
end
ensure
Result.entry_count <= entry_count
end
suffixed_by_item( entry : like item ) : like Current is
--the list, suffixed by a single item
require
is_valid_entry( entry )
do
!!Result.make_from_list( Current )
Result.add_entry( entry )
ensure
Result.entry_count = entry_count + 1
end
set_field_count( new_field_count : INTEGER ) is
--sets the field count
require
entry_count = 0 or ( entry_count > 0 implies head.count = new_field_count )
do
field_count := new_field_count
ensure
field_count = new_field_count
end
is_valid_field_index( field_index : INTEGER ) : BOOLEAN is
--whether the given field index is valid
do
if entry_count = 0 then
Result := true
else
Result := ( ( 1 <= field_index ) and ( field_index <= field_count ) )
end
end
is_sorted_by( field_index : INTEGER ) : BOOLEAN is
--whether the list is sorted by the given field index
require
is_valid_field_index( field_index )
do
Result := true
if entry_count > 1 then
Result := ( head.item( field_index ) < tail.head.item( field_index ) )
and tail.is_sorted_by( field_index )
end
end
feature {ANY}
--chi-squared distribution calcs
variance( field_index : INTEGER; is_full_population : BOOLEAN ) : DOUBLE is
require
is_valid_field_index( field_index )
is_full_population implies entry_count > 0
( not is_full_population ) implies entry_count > 1
local
divisor : DOUBLE
adder : ADDER
square : SQUARE
do
if is_full_population then
divisor := entry_count.to_double
else
divisor := (entry_count - 1).to_double
end
!!adder.make( - mean_by_field( field_index ) )
!!square
Result := ( mapped_to( field_index, adder ).
mapped_to( field_index, square ).
sum_by_field( field_index ) ) / divisor
end
standard_deviation( field_index : INTEGER; is_full_population : BOOLEAN ) : DOUBLE is
require
is_valid_field_index( field_index )
do
Result := variance( field_index, is_full_population ).sqrt
end
normalized_series( field_index : INTEGER ) : like Current is
--one series of the table, "normalized" into standard deviations
require
is_valid_field_index( field_index )
local
normalizer : NORMALIZER
do
!!normalizer.make( mean_by_field( field_index ), standard_deviation( field_index, false ) )
Result := mapped_to( field_index, normalizer ).select_series( field_index )
ensure
Result.entry_count = entry_count
end
normalization_s_value : INTEGER is
--number of segments in a normalization table
require
entry_count.divisible( 5 )
do
Result := entry_count // 5
end
normalized_series_table( field_index : INTEGER ) : like Current is
--a normalized series table, used for error-checking and used
--in the chi-squared normalization test
require
entry_count > 0
is_valid_field_index( field_index )
local
sorted_list : like Current
sorted_normalized_list : like Current
i : INTEGER
new_entry : ARRAY[ DOUBLE ]
do
sorted_list := sorted_by( field_index )
sorted_normalized_list := sorted_list.normalized_series( field_index )
check
sorted_list.entry_count = entry_count
sorted_normalized_list.entry_count = entry_count
end
from
i := sorted_list.lower
!!Result.make
until
not sorted_list.valid_index( i )
loop
!!new_entry.make( 1, 0 )
new_entry.add_last( i.to_double )
new_entry.add_last( i.to_double / entry_count.to_double )
new_entry.add_last( sorted_list.item( i ).item( field_index ) )
new_entry.add_last( sorted_normalized_list.item(i).first )
Result.add_entry( new_entry )
i := i + 1
end
end
normal_distribution_segments( s : INTEGER ) : like Current is
--segments of the normal distribution; see [Humphrey95] for use
require
s > 0
local
i : INTEGER
new_entry : ARRAY[ DOUBLE ]
norm_inverse : NORMAL_DISTRIBUTION_INVERSE
do
from
i := 1
!!Result.make
!!norm_inverse
until
i > s
loop
!!new_entry.make( 1, 0 )
if i = 1 then
new_entry.add_last( -1000.0 )
else
new_entry.add_last( norm_inverse.at( ( i - 1 ).to_double * ( 1.0 / s.to_double ) ) )
end
if i = s then
new_entry.add_last( 1000.0 )
else
new_entry.add_last( norm_inverse.at( ( i.to_double * 1.0 / s.to_double ) ) )
end
Result.add_entry( new_entry )
i := i + 1
end
end
chi_squared_table( field_index : integer ) : like Current is
-- chi-squared table, used to calculate the chi-squared distribution
require
is_valid_field_index( field_index )
local
norm_segments : like Current
norm_table : like Current
i : INTEGER
new_entry : ARRAY[ DOUBLE ]
do
from
norm_segments := normal_distribution_segments( normalization_s_value )
norm_table := normalized_series_table( field_index )
!!Result.make
i := norm_segments.lower
until
not norm_segments.valid_index( i )
loop
!!new_entry.make( 1, 0 )
new_entry.add_last( i.to_double )
new_entry.add_last( norm_segments.item( i ).item( 1 ) )
new_entry.add_last( norm_segments.item( i ).item( 2 ) )
new_entry.add_last( norm_table.entry_count.to_double / norm_table.normalization_s_value.to_double )
new_entry.add_last( norm_table.items_in_range( 4, new_entry.item(2), new_entry.item(3) ))
new_entry.add_last( ( new_entry.item(4) - new_entry.item(5) ) ^ 2 )
new_entry.add_last( new_entry.item(6) / new_entry.item(4) )
Result.add_entry( new_entry )
i := i + 1
end
end
chi_squared_q( field_index : INTEGER ) : DOUBLE is
--"Q" value of chi-squared normalization test
do
Result := chi_squared_table( field_index ).sum_by_field( 7 )
end
chi_squared_1_minus_p( field_index : INTEGER ) : DOUBLE is
--1-p value of chi-squared normalization test
local
chi_squared_integral : CHI_SQUARED_INTEGRAL
do
!!chi_squared_integral.make( normalization_s_value - 1 )
Result := 1 - chi_squared_integral.at( chi_squared_q( field_index ) )
end
select_series( field_index : INTEGER ) : like Current is
--the given series, extracted as a separate list
require
is_valid_field_index( field_index )
local
new_entry : ARRAY[ DOUBLE ]
do
if ( entry_count = 0 ) then
!!Result.make
else
!!new_entry.make( 1, 0 )
new_entry.add_last( head.item( field_index ) )
!!Result.make_from_entry( new_entry )
if entry_count > 1 then
Result := Result.suffixed_by_list( tail.select_series( field_index ) )
end
end
end
items_in_range( field_index : INTEGER; lower_limit, upper_limit : DOUBLE ) : INTEGER is
--the items from the given field which fit in (lower limit < item <= upper_limit)
require
is_valid_field_index( field_index )
do
if entry_count > 0 and head.item(field_index) > lower_limit and upper_limit >= head.item( field_index ) then
Result := 1
end
if entry_count > 1 then
Result := Result + tail.items_in_range( field_index, lower_limit, upper_limit )
end
end
entry_as_string( entry : like item ) : STRING is
--entry as a string, ie "( 1, 2, 3 )"
local
i : INTEGER
do
!!Result.make_from_string( "( " )
from
i := entry.lower
until
not entry.valid_index( i )
loop
entry.item( i ).append_in( Result )
if entry.valid_index( i + 1 ) then
Result.append_string( ", " )
end
i := i + 1
end
Result.append_string( " )" )
end
table_as_string : STRING is
--table, as a set of entry_as_string lines
do
if entry_count > 0 then
Result := entry_as_string( head ) + "%N"
if entry_count > 1 then
Result.append_string( tail.table_as_string )
end
end
end
end
|
number_array_list_parser_2.e
class NUMBER_ARRAY_LIST_PARSER_2
--reads a list of number pairs, and performs linear regression analysis
inherit
SIMPLE_INPUT_PARSER
redefine parse_last_line, transformed_line
end;
creation {ANY}
make
feature {ANY}
inline_comment_begin: STRING is "--";
string_stripped_of_comment(string: STRING): STRING is
--strip the string of any comment
local
comment_index: INTEGER;
do
if string.has_string(inline_comment_begin) then
comment_index := string.index_of_string(inline_comment_begin);
if comment_index = 1 then
!!Result.make_from_string( "" );
else
Result := string.substring(1,comment_index - 1);
end;
else
Result := string.twin;
end;
end -- string_stripped_of_comment
string_stripped_of_whitespace(string: STRING): STRING is
--strip string of whitespace
do
Result := string.twin;
Result.left_adjust;
Result.right_adjust;
end -- string_stripped_of_whitespace
transformed_line(string: STRING): STRING is
--strip comments and whitespace from parseable line
do
Result := string_stripped_of_whitespace(string_stripped_of_comment(string));
end -- transformed_line
number_list: NUMBER_ARRAY_LIST;
state : INTEGER
Parsing_historical_data : INTEGER is unique
Parsing_commands : INTEGER is unique
Command_normality_check_on_series : STRING is
once
Result := "normality_check_on_series"
end
historical_data_terminator: STRING is "stop";
double_from_string(string: STRING): DOUBLE is
require
string.is_double or string.is_integer;
do
if string.is_double then
Result := string.to_double;
elseif string.is_integer then
Result := string.to_integer.to_double;
end;
end -- double_from_string
feature {ANY} --parsing
reset is
--resets the parser and makes it ready to go again
do
state := Parsing_historical_data;
number_list.make;
end -- reset
make is
do
!!number_list.make;
reset;
end -- make
parse_last_line_as_historical_data is
--interpret last_line as a pair of comma-separated values
local
error_log: ERROR_LOG;
this_line_numbers : ARRAY[ DOUBLE ]
do
!!error_log.make
if last_line_is_valid_historical_data then
this_line_numbers := numbers_from_string( last_line )
number_list.add_entry( this_line_numbers )
else
error_log.log_error( "Invalid historical data: " + last_line + "%N" )
end
end
parse_last_line_as_end_of_historical_data is
--interpret last line as the end of historical data
require
last_line.compare(historical_data_terminator) = 0;
local
i : INTEGER
do
state := Parsing_commands
std_output.put_string( "Historical data read; " + number_list.entry_count.to_string +
"items read%N" )
end -- parse_last_line_as_end_of_historical_data
parse_last_line_as_command is
--interpret the last line as a command
local
command : STRING
arguments : ARRAY[ STRING ]
do
command := string_before_separator( last_line, " " )
arguments := split_string( string_after_separator( last_line, " ", ), " " )
if command.is_equal( Command_normality_check_on_series ) then
print_normalization_check_on_series( arguments.first.to_integer + 1)
else
std_output.put_string( "Unrecognized command string: " + last_line )
end
end
parse_last_line is
--parse the last line according to state
do
if not last_line.empty then
if state = Parsing_historical_data then
if last_line.compare(historical_data_terminator) = 0 then
parse_last_line_as_end_of_historical_data;
else
parse_last_line_as_historical_data;
end;
else
parse_last_line_as_command
end
end;
end -- parse_last_line
last_line_is_valid_historical_data : BOOLEAN is
--whether last line is valid historical data
local
substrings : ARRAY[ STRING ]
i : INTEGER
do
substrings := split_string( last_line, "," )
Result := true
if ( number_list.entry_count > 0 and substrings.count /= number_list.field_count ) then
Result := false;
end
--check and see if each substring is convertible to a double
from
i := substrings.lower
until
not substrings.valid_index( i )
loop
if not ( substrings.item(i).is_double or substrings.item(i).is_integer ) then
Result := false;
end
i := i + 1
end
end
split_string( string_to_split, separator : STRING ) : ARRAY[ STRING ] is
--a list of components of a string, separated by the given
--separator, ie split_string( "1,2,3", "," ) = [ "1", "2", "3" ]
local
prior_to_separator : STRING
remainder : STRING
split_remainder : ARRAY[ STRING ]
i : INTEGER
do
prior_to_separator := string_before_separator( string_to_split, separator )
remainder := string_after_separator( string_to_split, separator )
!!Result.make( 1, 0 )
Result.add_last( prior_to_separator )
if remainder.count > 0 then
split_remainder := split_string( remainder, separator )
from
i := split_remainder.lower
until
not split_remainder.valid_index( i )
loop
Result.add_last( split_remainder.item( i ) )
i := i + 1
end
end
end
string_before_separator( string_to_split, separator : STRING ) : STRING is
--the part of a string which comes before the separator, or
--the whole string if it's not found
local
separator_index : INTEGER
do
separator_index := string_to_split.substring_index( separator, 1 )
if ( separator_index = 0 ) then
--not found; copy whole string
Result := string_to_split.twin
else
Result := string_to_split.substring( 1, separator_index - 1 )
end
end
string_after_separator( string_to_split, separator : STRING ) : STRING is
--the part of the string after the separator,
local
separator_index : INTEGER
do
separator_index := string_to_split.substring_index( separator, 1 )
if ( separator_index = 0 ) then
--not found; result is empty
!!Result.make_from_string( "" )
else
Result := string_to_split.substring( separator_index + separator.count, string_to_split.count )
end
end
numbers_from_string( string_to_split : STRING ) : ARRAY[ DOUBLE ] is
--an array of numbers, from a string of numbers separated by commas
local
number_strings : ARRAY[ STRING ]
i : INTEGER
do
!!Result.make( 1, 0 )
number_strings := split_string( string_to_split, "," )
from
i := number_strings.lower
until
not number_strings.valid_index( i )
loop
check
number_strings.item(i).is_double or number_strings.item(i).is_integer
end
Result.add_last( double_from_string( number_strings.item( i ) ) )
i := i + 1
end
end
print_normalization_check_on_series( field_index : INTEGER ) is
do
std_output.put_string( "Normalization check on series " )
std_output.put_integer( field_index )
--std_error.put_string( number_list.sorted_by( field_index ).table_as_string + "%N" )
--std_error.put_string( number_list.normalized_series_table( field_index ).table_as_string )
std_output.put_string( "%NQ: " )
std_output.put_double( number_list.chi_squared_q( field_index ) )
std_output.put_string( "%N(1-p): ")
std_output.put_double( number_list.chi_squared_1_minus_p( field_index ) )
std_output.put_new_line
end
end -- class NUMBER_ARRAY_LIST_PARSER_2
|
main.e
class MAIN
creation {ANY}
make
feature {ANY}
make is
local
parser: NUMBER_ARRAY_LIST_PARSER_2;
do
!!parser.make;
parser.set_input(io);
parser.parse_until_eof;
end -- make
end -- MAIN |
Code Review
I need to get better at code reviews. On both the Eiffel and C++ side, I missed several obvious problems-- on the Eiffel side, a problem which caused a great deal of delay (I had forgotten that Eiffel programs only copy by reference, and I had copied something and changed it, changing the original-- and completely baffling me for some time-- something to add to my code review checklist!)
Compile
Once again, the compiler caught many sneaky items. I'm impressed by the error-checking in the Eiffel compiler, particularly with regard to type compliance-- it caught several small things which I just didn't notice in the code review (including the fact that one of my comments was mismatched!). Very nice.
Test
My strategy of reproducing the calculation tables as in the text paid good dividends here, as I was able to print out the tables and search for problems. It worked very well, and though I had several problems with the programs themselves, they were relatively easy to find and fix due to the availability of interim values, etc.
Table 10-2. D15: Test Results Format -- program 9a
| Test | Expected Result | Actual Result - C++ | Actual Result - Eiffel |
| Table D14 | |||
| Q | 34.4 | 34.4 | 34.400000 |
| 1-p | 7.60*10-5 | 7.61098e-05 | 0.000079 |
I'm curious about the difference in calculation between the C++ and Eiffel programs with regard t othe 1-p entry; the values are extremely close, and I can't find significant differences in the calculations, but something seems a touch off kilter. I can't figure out if it's the level of precision involved, a difference in standard libraries, or what.
Postmortem
PSP2.1 Project Plan Summary
Table 10-3. Project Plan Summary
| Student: | Victor B. Putz | Date: | 000201 |
| Program: | Normalization | Program# | 9A |
| Instructor: | Wells | Language: | C++ |
| Summary | Plan | Actual | To date |
| Loc/Hour | 46 | 45 | 46 |
| Planned time | 285 | 943 | |
| Actual time | 342 | 1248 | |
| CPI (cost/performance index) | 0.76 | ||
| %reused | 47 | 69 | 46 |
| Test Defects/KLOC | 31 | 27 | 30.6 |
| Total Defects/KLOC | 141 | 135 | 140.4 |
| Yield (defects before test/total defects) | 78 | 80 | 78 |
| % Appraisal COQ | 5 | 8.5 | 5.58 |
| % Failure COQ | 29.8 | 19.6 | 28.32 |
| COQ A/F Ratio | 0.16 | 0.43 | 0.20 |
| Program Size | Plan | Actual | To date |
| Base | 20 | 20 | |
| Deleted | 0 | 18 | |
| Modified | 1 | 1 | |
| Added | 237 | 257 | |
| Reused | 231 | 565 | 1698 |
| Total New and Changed | 239 | 258 | 1731 |
| Total LOC | 489 | 824 | 3672 |
| Upper Prediction Interval (70%) | 326 | ||
| Lower Prediction Interval (70%) | 152 |
| Time in Phase (min): | Plan | Actual | To Date | To Date% |
| Planning | 54 | 77 | 449 | 20 |
| Design | 37 | 67 | 314 | 14 |
| Design Review | 6 | 13 | 53 | 2 |
| Code | 74 | 78 | 568 | 25 |
| Code Review | 9 | 16 | 73 | 3 |
| Compile | 17 | 18 | 132 | 6 |
| Test | 68 | 49 | 507 | 22 |
| Postmortem | 20 | 24 | 160 | 7 |
| Total | 285 | 342 | 2256 | 100 |
| Total Time UPI (70%) | 322 | |||
| Total Time LPI (70%) | 249 | |||
| Defects Injected | Actual | To Date | To Date % | |
| Plan | 0 | 0 | 0 | |
| Design | 10 | 12 | 77 | 32 |
| Design Review | 0 | 0 | 0 | 0 |
| Code | 22 | 23 | 160 | 66 |
| Code Review | 0 | 0 | 0 | 0 |
| Compile | 1 | 0 | 3 | 1 |
| Test | 1 | 0 | 3 | 1 |
| Total development | 34 | 35 | 243 | 100 |
| Defects Removed | Actual | To Date | To Date % | |
| Planning | 0 | 0 | 0 | |
| Design | 0 | 0 | 0 | |
| Design Review | 1 | 6 | 15 | 6 |
| Code | 7 | 1 | 45 | 19 |
| Code Review | 3 | 8 | 23 | 9 |
| Compile | 15 | 13 | 107 | 44 |
| Test | 8 | 7 | 53 | 22 |
| Total development | 34 | 35 | 243 | 100 |
| After Development | 0 | 0 | 0 | |
| Defect Removal Efficiency | Plan | Actual | To Date | |
| Defects/Hour - Design Review | 13.5 | 27.6 | 22.5 | |
| Defects/Hour - Code Review | 15.8 | 30 | 24.2 | |
| Defects/Hour - Compile | 49.5 | 43.3 | 56.3 | |
| Defects/Hour - Test | 6 | 8.57 | 6.9 | |
| DRL (design review/test) | 2.25 | 3.22 | 2.26 | |
| DRL (code review/test) | 2.63 | 3.5 | 3.5 | |
| DRL (compile/test) | 8.25 | 5.05 | 8.16 |
| Eiffel code/compile/test |
| Time in Phase (min) | Actual | To Date | To Date % |
| Code | 62 | 369 | 50 |
| Code Review | 10 | 40 | 6 |
| Compile | 15 | 133 | 18 |
| Test | 41 | 192 | 26 |
| Total | 128 | 734 | 100 |
| Defects Injected | Actual | To Date | To Date % |
| Design | 1 | 6 | 4 |
| Code | 22 | 138 | 95 |
| Compile | 0 | 0 | 0 |
| Test | 0 | 1 | 1 |
| Total | 23 | 145 | 100 |
| Defects Removed | Actual | To Date | To Date % |
| Code | 0 | 1 | 1 |
| Code Review | 9 | 14 | 11 |
| Compile | 16 | 88 | 60 |
| Test | 5 | 40 | 28 |
| Total | 23 | 145 | 100 |
| Defect Removal Efficiency | Actual | To Date | |
| Defects/Hour - Code Review | 12 | 24 | |
| Defects/Hour - Compile | 64 | 40 | |
| Defects/Hour - Test | 7.3 | 12.5 | |
| DRL (code review/test) | 1.6 | 1.9 | |
| DRL (compile/test) | 8.8 | 3.2 |
Time Recording Log
Table 10-4. Time Recording Log
| Student: | Victor B. Putz | Date: | 000130 |
| Program: | 9a |
| Start | Stop | Interruption Time | Delta time | Phase | Comments |
| 000130 10:50:04 | 000130 12:07:06 | 0 | 77 | plan | |
| 000130 12:14:58 | 000130 13:25:57 | 4 | 66 | design | |
| 000130 13:59:50 | 000130 14:12:30 | 0 | 12 | design review | |
| 000130 14:24:05 | 000130 15:50:58 | 9 | 77 | code | |
| 000130 16:00:00 | 000130 16:21:52 | 5 | 16 | code review | |
| 000130 16:22:00 | 000130 16:39:45 | 0 | 17 | compile | |
| 000130 16:42:18 | 000130 17:31:05 | 0 | 48 | test | |
| 000130 17:31:29 | 000130 17:55:28 | 0 | 23 | postmortem | |
Table 10-5. Time Recording Log
| Student: | Date: | 000201 | |
| Program: |
| Start | Stop | Interruption Time | Delta time | Phase | Comments |
| 000201 07:56:14 | 000201 09:00:44 | 2 | 62 | code | |
| 000201 09:01:18 | 000201 09:11:07 | 0 | 9 | code review | |
| 000201 09:11:20 | 000201 09:26:12 | 0 | 14 | compile | |
| 000201 09:26:36 | 000201 10:07:25 | 0 | 40 | test | |
Defect Reporting Logs
Table 10-6. Defect Recording Log
| Student: | Victor B. Putz | Date: | 000130 |
| Program: | 9a |
| Defect found | Type | Reason | Phase Injected | Phase Removed | Fix time | Comments |
| 000130 13:59:52 | ct | ig | design | design review | 1 | missed minor contracts |
| 000130 14:03:53 | ma | ig | design | design review | 0 | didn't increment loop indices |
| 000130 14:05:35 | ct | ig | design | design review | 0 | missed contract for variance |
| 000130 14:07:06 | ct | ig | design | design review | 0 | require standard_deviation /= 0 |
| 000130 14:07:58 | ct | ig | design | design review | 0 | require s > 0 in normal_distribution_segments |
| 000130 14:09:41 | ct | ig | design | design review | 0 | minor contracts |
| 000130 15:44:53 | md | ig | design | code | 0 | forgot to add parse_last_line_as_command |
| 000130 16:02:40 | ct | ig | code | code review | 0 | forgot to put in the require contract for make/constructor |
| 000130 16:05:07 | sy | om | code | code review | 0 | forgot to #include normal_distribution_integral |
| 000130 16:06:00 | sy | om | code | code review | 0 | forgot to make last_guess const in implementation |
| 000130 16:13:33 | sy | om | code | code review | 0 | forgot to return return value! |
| 000130 16:17:23 | wc | om | code | code review | 0 | was testing the integral of the normal distribution as 100, rather than 1 |
| 000130 16:19:06 | sy | ty | code | code review | 0 | forgot parentheses around no-argument operation |
| 000130 16:19:53 | sy | ty | code | code review | 0 | forgot parentheses around no-argument operation |
| 000130 16:20:27 | sy | om | code | code review | 0 | forgot to return return value! |
| 000130 16:23:13 | sy | ig | design | compile | 6 | er... forgot that inheriting and mixing types gets very gross; combined number_array_list and number_array_list_2 into one |
| 000130 16:30:48 | wn | ty | code | compile | 0 | misspelled normal_distribution_inverse |
| 000130 16:31:54 | wn | cm | code | compile | 0 | used normalized_series_table instead of norm_table |
| 000130 16:33:25 | sy | cm | code | compile | 0 | didn't make the at function const as required |
| 000130 16:34:07 | sy | cm | code | compile | 0 | missed parentheses on no-arg function |
| 000130 16:34:40 | sy | cm | code | compile | 0 | forgot return type for select_series |
| 000130 16:35:05 | sy | ty | code | compile | 0 | declared Result with type::Result |
| 000130 16:35:34 | sy | om | code | compile | 0 | forgot const in implementation |
| 000130 16:35:57 | wn | cm | code | compile | 0 | er.. didn't type the correct name for the argument |
| 000130 16:36:17 | sy | om | code | compile | 0 | forgot parentheses for no-arg function |
| 000130 16:36:58 | sy | cm | code | compile | 0 | mistyped integer instead of int |
| 000130 16:37:57 | sy | om | code | compile | 0 | forgot to #include gamma_function.h |
| 000130 16:38:22 | sy | om | code | compile | 0 | forgot to #include simpson_integrator.h |
| 000130 16:45:22 | wc | om | code | test | 0 | had to add an exception that if the first guess was in, don't try a second guess! |
| 000130 16:46:46 | ct | om | design | test | 0 | forgot contract in normalized_series and select_series |
| 000130 16:52:18 | ct | om | design | test | 0 | forgot ensure contract in normalized_series_table |
| 000130 16:53:01 | wn | ty | code | test | 1 | was setting an iterator to end instead of begin for startup |
| 000130 16:56:12 | we | ig | design | test | 7 | was using field_index as index of normalized series, instead of zero index |
| 000130 17:07:17 | sy | ig | code | test | 14 | dangit-- C++ was doing silent conversions from int to double without thinking |
| 000130 17:21:45 | wa | ig | design | test | 8 | was not setting the correct degrees of freedom for chi2 integral |
Table 10-7. Defect Recording Log
| Student: | Date: | 000201 | |
| Program: |
| Defect found | Type | Reason | Phase Injected | Phase Removed | Fix time | Comments |
| 000201 09:04:25 | ct | om | code | code review | 0 | forgot to put in comment |
| 000201 09:07:29 | wn | cm | code | code review | 0 | forgot to change "Parsing_prediction_data" to "Parsing_commands" |
| 000201 09:11:30 | sy | ig | code | compile | 0 | forgot that comments which end a class must be correct! |
| 000201 09:12:08 | sy | cm | code | compile | 0 | separated arguments of different type with comma rather than semicolon |
| 000201 09:12:44 | sy | om | code | compile | 0 | accidentally put contract under the local block |
| 000201 09:13:20 | wn | om | code | compile | 0 | forgot to qualify item with feature call |
| 000201 09:14:05 | sy | ty | code | compile | 0 | forgot colon before return value |
| 000201 09:15:14 | sy | ty | code | compile | 0 | forgot "is" after feature declaration |
| 000201 09:15:39 | wa | cm | code | compile | 1 | forgot to take out program 8a code to print the sorted lists |
| 000201 09:17:11 | wn | ig | code | compile | 0 | used "equals" instead of "is_equal" for string equality test |
| 000201 09:18:29 | wn | cm | code | compile | 0 | used "lower" instead of "first" for first argument of an array |
| 000201 09:19:12 | wn | cm | code | compile | 0 | typed "entry" instead of "new_entry" |
| 000201 09:19:49 | wn | cm | code | compile | 0 | typed "i" rather than "field_index" |
| 000201 09:20:12 | wn | cm | code | compile | 0 | typed "n" rather than "entry_count" |
| 000201 09:21:16 | wn | ig | code | compile | 0 | apparently "/" is used to produce a double from two integers; // is what I wanted |
| 000201 09:22:04 | sy | ig | code | compile | 0 | used "is" in local block |
| 000201 09:23:11 | wt | ig | code | compile | 0 | urg... returned a double rather than an integer |
| 000201 09:25:52 | mc | cm | code | compile | 0 | was not instantiating my normal_distribution_inverse object |
| 000201 09:27:00 | wc | cm | design | test | 1 | wrong value (100 instead of 1) in normal_distribution_segments |
| 000201 09:29:20 | ct | ty | code | test | 2 | was doing test on old value of n, not new value! |
| 000201 09:33:55 | ma | om | code | test | 0 | forgot to update i in loop! |
| 000201 09:35:00 | wa | ig | code | test | 7 | |
| 000201 09:45:46 | wa | ig | code | test | 20 | Okay, this hurt-- forgot that Eiffel doesn't copy things by default, so I was modifying the original list! |